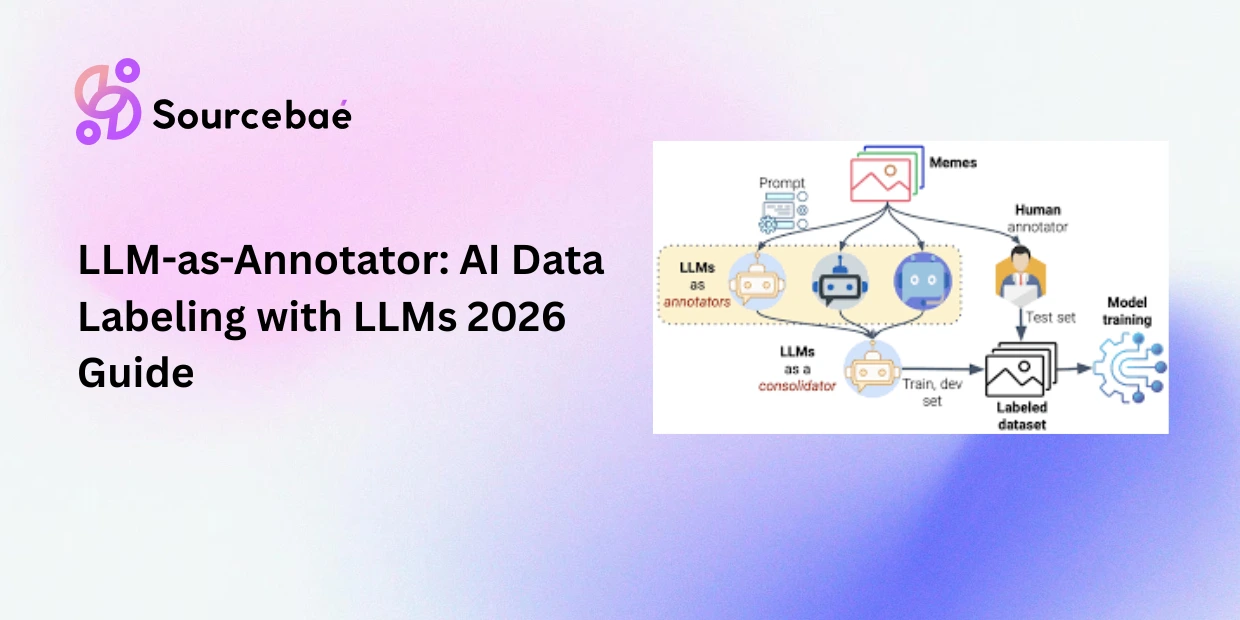
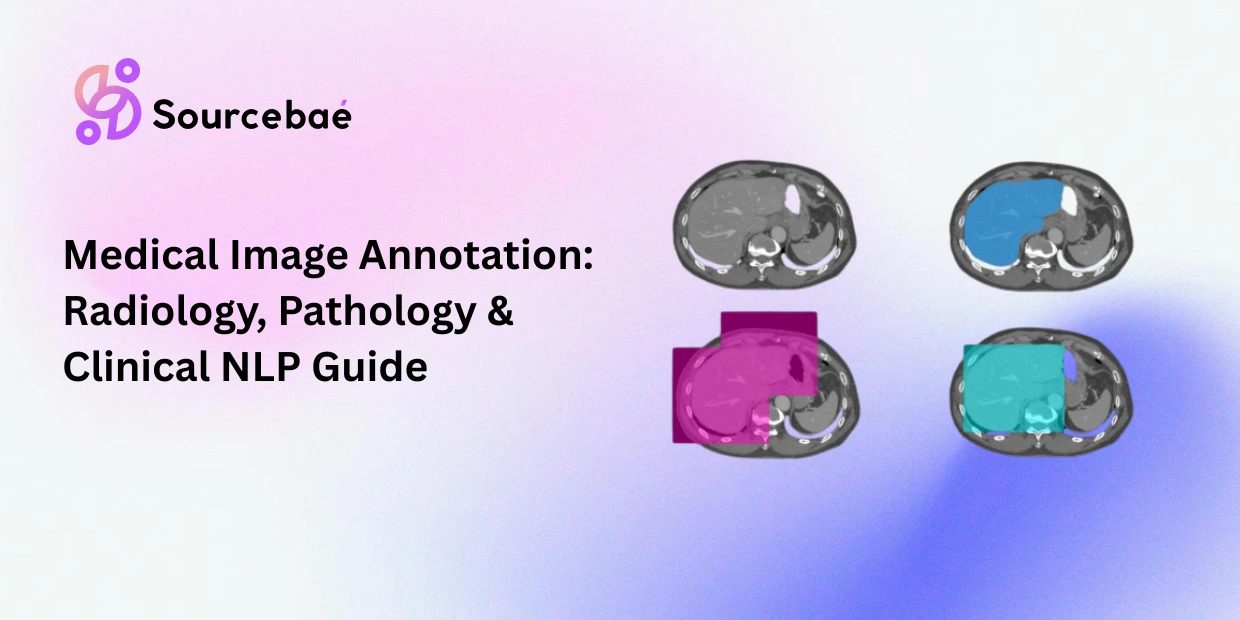
In the realm of machine learning, decision trees are an indispensable tool for problem-solving and decision-making.
These trees provide a visual representation of potential choices, outcomes, and their associated probabilities. With their ability to handle both categorical and numerical data, decision trees can be a powerful asset in various domains.
In this article, we will explore what decision trees are, how they work, their advantages and disadvantages, different types, and applications, and ultimately delve into their role in machine learning.
What are Decision Trees?
Decision trees are hierarchical structures built using nodes and edges. Each internal node represents a feature or attribute, branches emanate from these nodes, and leaf nodes represent the outcomes or decisions. These trees facilitate data analysis by sequentially partitioning the data based on the selected features until a final decision is reached. Each branch corresponds to a range or category, guiding the decision-making process effectively.
How do Decision Trees Work?
The working principle of decision trees revolves around finding the most optimal splits in the dataset. The splitting criterion depends on various algorithms such as Gini Index, Information Gain, or Chi-Square Test. The tree-building algorithm recursively selects features and thresholds to create binary splits, aiming to maximize the information gained or minimize impurity at each node. This process continues until the desired depth or purity level is attained.
Advantages of Decision Trees
Decision trees offer several advantages that make them appealing in the field of machine learning. Firstly, they are easy to understand and interpret, making them accessible even to non-experts. Additionally, decision trees can handle both numerical and categorical data, allowing for great flexibility in different domains. They are also capable of handling missing values and outliers efficiently. Furthermore, decision trees can be visualized, providing clear insights and explanations for decision-making.
Disadvantages of Decision Trees
Despite their many advantages, decision trees also have their limitations. One of the drawbacks is their tendency to overfit the training data, resulting in suboptimal performance on new, unseen data. Decision trees are also susceptible to small changes in the dataset, potentially leading to different tree structures. Additionally, complex decision trees can become difficult to comprehend and prone to inducing biased or inaccurate predictions.
Types of Decision Trees
Decision trees can be categorized into various types based on their characteristics and purposes. Some common types include binary decision trees, multi-output decision trees, regression trees, classification trees, and random forests. Each type has its unique features and applications, catering to different problem domains.
Applications of Decision Trees
Decision trees have found relevance in a wide range of applications. In finance, they are used for credit scoring and investment analysis. In medicine, decision trees aid in diagnosing diseases and predicting patient outcomes. In customer relationship management, decision trees help with customer segmentation and churn prediction. Other domains, such as marketing, manufacturing, and fraud detection, also benefit from the applications of decision trees.
Decision Trees in Machine Learning
In machine learning, decision trees play a vital role in both classification and regression tasks. They can classify data into distinct classes or predict continuous target variables based on the provided features. Decision trees are versatile and commonly used in ensemble methods like random forests, boosting, and bagging. Their interpretability and ability to handle both categorical and numerical data make them a preferred choice for many machine learning practitioners.
Building Decision Trees
Building decision trees involves several steps. First, the dataset needs to be divided into a training set and a test set. The training set is used to construct the decision tree, while the test set is used to evaluate its performance. Various algorithms and heuristics, such as ID3, C4.5, or CART, can be used to create the tree structure. These algorithms handle attribute selection, pruning, and depth constraints to generate an optimal decision tree.
Evaluating Decision Trees
To assess the accuracy and effectiveness of decision trees, several evaluation metrics are employed. These include accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC-ROC). Cross-validation techniques like k-fold cross-validation and stratified sampling can help in obtaining more reliable performance estimates.
Improving Decision Trees
To improve the performance of decision trees, several strategies can be employed. Pruning, which involves removing unnecessary branches or nodes, helps prevent overfitting and improves generalization. Ensemble methods like random forests combine multiple decision trees to obtain more accurate and robust predictions. Feature selection techniques and hyperparameter tuning also contribute to enhancing the overall performance of decision trees.
Conclusion
Decision trees stand as a powerful tool in machine learning, aiding in decision-making processes and problem-solving across various domains. Their interpretability, adaptability, and ability to handle diverse data make them a valuable asset for both beginners and experts in the field. Despite their limitations, decision trees continue to play a pivotal role in transforming data into meaningful insights.
FAQs
FAQ 1:
What are the key advantages of using decision trees in machine learning?
Decision trees offer several advantages in machine learning. They are easy to understand and interpret, handle both categorical and numerical data, and visualize the decision-making process. Additionally, decision trees can handle missing values efficiently.
FAQ 2:
What are the limitations of decision trees in machine learning?
Decision trees can overfit the training data, resulting in poor performance on new data. They are also sensitive to small changes in the dataset, and complex decision trees can be difficult to comprehend.
FAQ 3:
What types of decision trees exist?
Some common types of decision trees include binary decision trees, multi-output decision trees, regression trees, classification trees, and random forests. Each type has its own specific applications and characteristics.
FAQ 4:
In what domains are decision trees commonly used?
Decision trees find relevance in various domains such as finance, medicine, customer relationship management, marketing, manufacturing, and fraud detection, among others.
FAQ 5:
How can decision trees be improved in machine learning?
Decision tree performance can be improved through techniques such as pruning, ensemble methods like random forests, feature selection, and hyperparameter tuning.
In conclusion, decision trees form an integral part of machine learning, aiding in effective decision-making and problem-solving. With their versatility and interpretability, they continue to be a popular choice in various domains.