Human-in-the-loop annotation is a methodology that embeds human judgment directly into the AI training and deployment lifecycle. It is not a one-time labeling step. Instead, it serves as a continuous feedback mechanism. Humans review, correct, and validate machine outputs at every stage from initial data labeling through production monitoring. In 2026, HITL annotation has become the operational standard. It applies to any AI system where accuracy, safety, or regulatory compliance matters.
Here is the paradox that defines this moment: the more advanced AI becomes, the more it depends on high-quality human input. As models grow more capable, they enter higher-stakes settings. These include medical diagnosis, autonomous vehicles, financial decision-making, and content moderation at scale. In these domains, errors are measured in patient outcomes, safety incidents, and regulatory penalties. Edge cases may represent only 1–2% of the data an AI system encounters. Yet they account for a disproportionate share of real-world failures. A self-driving system that performs flawlessly 98% of the time but misclassifies a pedestrian in unusual lighting has a fatal problem not a marginal one. Human oversight is what catches, labels, and feeds those critical edge cases back into the system.
This post defines what human-in-the-loop means in practice. It explains the continuous feedback loop that distinguishes HITL from traditional annotation. It covers edge case handling, production monitoring, and escalation frameworks. Its also addresses annotator expertise requirements and cost-benefit analysis. Together, these show why HITL is not just a quality measure but an economic necessity.
Defining Human-in-the-Loop Annotation
Human-in-the-loop machine learning is a collaborative approach. Humans actively participate in training, evaluating, and operating AI systems. They provide the guidance, feedback, and domain expertise that models cannot generate on their own. The term describes a system architecture, not a single activity. HITL encompasses data annotation, output verification, error correction, edge case handling, and ongoing model monitoring.
The critical distinction is between HITL and traditional annotation. Traditional annotation is a batch process: humans label a dataset, the model trains on it, and the humans are done. HITL annotation is a continuous process. Humans participate before training by labeling initial data. During training, they correct model predictions. After deployment, they review production outputs and flag failures. This continuity is what makes HITL effective. The model never stops receiving human signal. And the human never stops learning what the model gets wrong.
Two related concepts clarify the spectrum of human involvement. Human-on-the-loop (HOTL) describes a supervisory role where humans monitor an autonomous system and intervene only when it deviates from expected behavior like a safety operator in a self-driving vehicle. Human-out-of-the-loop (HOOTL) describes full automation where humans have no real-time involvement. Most production AI systems in 2026 operate somewhere between HITL and HOTL, with the level of human involvement calibrated to the risk and complexity of each decision. (For the foundational annotation principles that underpin any HITL workflow, see our [comprehensive guide to data annotation Pillar Page].)
The Continuous Feedback Loop
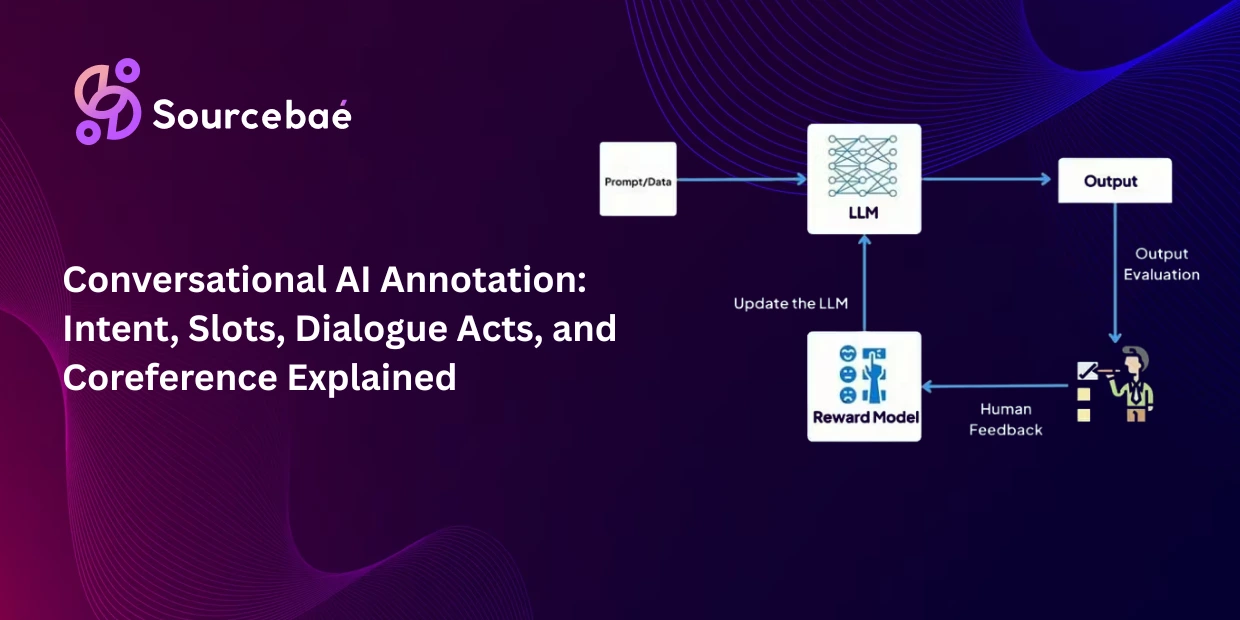
The defining architectural feature of HITL annotation is the feedback loop a cycle in which model outputs flow to humans for review, human corrections flow back to improve the model, and the improved model produces better outputs for the next cycle.
The loop has four stages.
Stage 1: Model prediction. The AI system generates an output a classification, a segmentation mask, a generated response, a routing decision. Each output carries a confidence score indicating how certain the model is about its prediction.
Stage 2: Human review. Outputs that fall below a confidence threshold, that trigger disagreement flags, or that are randomly sampled for quality auditing are routed to human reviewers. The reviewer examines the model’s output against the original data and either confirms the prediction, corrects it, or escalates it as an edge case requiring specialized expertise.
Stage 3: Feedback integration. The human corrections are collected, quality-checked, and integrated back into the training pipeline. Corrected predictions become new labeled training examples. Patterns of systematic errors inform model retraining priorities. Edge case collections become dedicated test sets that the model must pass before redeployment.
Stage 4: Model update. The model is retrained or fine-tuned on the expanded dataset, incorporating the human corrections. The updated model produces better predictions, reducing the volume of cases that require human review but generating a new set of edge cases at the frontier of its capability. The loop continues.
This cycle runs continuously in production HITL systems. It is not a one-time improvement it is the operating rhythm of the system. Each iteration improves the model’s performance on the cases humans corrected while surfacing new categories of difficulty. One industry analysis described HITL as creating “an ongoing dialogue between human intelligence and machine learning” rather than a one-time training followed by black-box deployment. The continuous nature of this dialogue is what prevents model collapse the gradual degradation of model performance that occurs when a model trains on its own outputs without fresh human signal.
Edge Case Annotation: The 1% That Causes 99% of Failures
Edge case annotation is the practice of identifying, collecting, and labeling the rare, unusual, or ambiguous examples that fall outside a model’s normal operating distribution. In human review AI labeling workflows, edge cases are the highest-value annotation targets because they represent the situations where the model is most likely to fail and where the consequences of failure are most severe.
What makes something an edge case
An edge case is any data point where the model’s training distribution does not adequately prepare it for the real-world input. In autonomous driving, this includes unusual weather conditions, objects in unexpected positions, rare vehicle types, and unusual pedestrian behavior. In content moderation, it includes culturally specific expressions, emerging slang, and content that sits ambiguously at the boundary of policy. Medical imaging, it includes rare pathologies, imaging artifacts, and anatomical variants.
Why edge cases are disproportionately important
A model’s aggregate accuracy metrics can look excellent while masking catastrophic failures on edge cases. A content moderation model that correctly classifies 99% of posts but misses the 1% containing the most harmful content has a serious problem. An autonomous vehicle perception system that identifies 99.5% of obstacles but misses unusual barrier configurations at intersections has a safety-critical gap. Edge cases are the long tail of the data distribution, and they are where AI systems fail in ways that matter.
The annotation challenge
Edge cases are difficult to annotate for several reasons. They are hard to find by definition, they are rare, and targeted collection strategies (adversarial testing, scenario simulation, production monitoring) are needed to surface them. They are hard to label edge cases often involve genuine ambiguity where reasonable experts might disagree, requiring adjudication protocols rather than simple majority-vote labeling. And they are hard to standardize the categories of edge cases evolve as the model improves, because each round of edge case annotation and retraining pushes the failure boundary to new, previously unseen scenarios. (For annotation quality frameworks that handle inter-annotator disagreement on ambiguous cases, see our post on [annotation quality and guidelines Post 4].)
HITL for Production Model Monitoring
HITL annotation does not end when the model is deployed. In production, HITL shifts from training-time annotation to monitoring-time validation humans reviewing the model’s live outputs to detect degradation, drift, and emerging failure modes.
Why production monitoring requires humans
Automated monitoring can detect statistical anomalies shifts in output distributions, drops in confidence scores, changes in prediction latency. But it cannot determine whether a shift represents a problem. A content moderation model that starts flagging more posts as toxic might be correctly detecting a trend in user behavior, or it might be hallucinating toxicity due to drift. Only a human reviewer can examine the flagged outputs, compare them against the policy, and determine whether the model’s behavior change is appropriate.
Monitoring-driven annotation
In mature HITL systems, production monitoring generates its own annotation workflow. The model logs every prediction with its confidence score. A monitoring system identifies outputs that are low-confidence, that represent novel patterns, or that users have challenged or reported. These outputs are routed to human annotators who label them creating a stream of fresh, production-relevant training data that keeps the model aligned with evolving real-world conditions.
Detecting model drift
Model drift occurs when the real-world data distribution shifts away from the distribution the model was trained on. Seasonal changes, evolving user behavior, new product categories, regulatory updates all of these can cause drift. HITL monitoring catches drift early because human reviewers notice when the model’s outputs stop making sense in context, long before statistical metrics register a significant change. The human reviewer’s domain knowledge is the earliest and most sensitive drift detector.
Fleet-level monitoring
For AI systems deployed at scale (fleets of autonomous vehicles, thousands of content moderation queues, hospital networks using the same diagnostic tool), HITL monitoring aggregates insights across all deployment instances. An edge case encountered by one instance is labeled once and benefits all instances. Error patterns detected in one deployment context trigger targeted review across all contexts. (For how this connects to broader annotation operations, see our post on [annotation project management and scaling Post 6].)
When to Escalate to Human Review
Not every model output needs human review that would negate the efficiency gains of automation. The art of HITL design is knowing when to escalate. Effective escalation frameworks balance coverage (catching enough errors) with efficiency (not overwhelming reviewers with routine cases).
Confidence-based escalation
routes any prediction below a calibrated confidence threshold to human review. This is the simplest and most widely used approach. The threshold must be tuned to the specific task: a threshold of 0.95 might be appropriate for a safety-critical system where any uncertainty warrants human review, while 0.70 might suffice for a low-stakes classification where occasional errors are acceptable.
Disagreement-based escalation
routes predictions where multiple models (or multiple inference passes) disagree. If an ensemble of models splits its vote or if self-consistency sampling produces conflicting labels, the case is flagged as ambiguous and routed to a human. This approach catches cases where the model is uncertain in ways that confidence scores alone may not capture.
Policy-based escalation
routes specific categories of predictions to human review regardless of confidence. In content moderation, any prediction involving potential child safety content might require mandatory human review. In medical AI, any diagnosis of a life-threatening condition might be escalated regardless of model confidence. These are non-negotiable escalation rules driven by risk tolerance, not model performance.
Anomaly-based escalation
routes inputs that look unusual data points that are statistically distant from the training distribution, inputs with unusual characteristics, or patterns that the monitoring system has not seen before. These may not trigger low confidence (the model may be confidently wrong on novel inputs), but their novelty makes them high-value review targets.
Sampling-based escalation
routes a random sample of all predictions to human review as an ongoing quality audit, even when no trigger criterion is met. This random sampling catches systematic biases and slow drift that targeted escalation might miss because they affect the model’s “easy” cases, not just its uncertain ones. (For how AI-assisted pre-labeling connects to these escalation workflows, see our post on [AI-assisted annotation Post 24].)
Annotator Expertise Requirements
The quality of HITL annotation is bounded by the qualifications of the humans in the loop. As AI systems are deployed in more specialized domains, the expertise bar for HITL annotators rises correspondingly.
Tiered expertise models.
Most production HITL systems use a tiered approach. General annotators handle routine review tasks confirming straightforward model predictions, correcting obvious errors, and performing first-pass quality checks. Domain specialists handle cases requiring subject matter expertise medical professionals reviewing diagnostic outputs, legal experts reviewing compliance classifications, engineers reviewing technical content. Senior adjudicators resolve disagreements between annotators and establish precedent for edge cases that the guidelines do not yet address.
The domain expert premium.
The shift toward specialized HITL annotators has significant cost implications. Expert annotation rates for medical, legal, and financial domains range from $50 to $200 per hour compared to $3–$60 per hour for general annotation tasks. This cost difference is not a luxury; it is the price of accuracy in domains where mislabeling has material consequences. The industry consensus in 2026 is that the cost of expert reviewers is substantially lower than the cost of deploying a model with errors that expert review would have caught.
Calibration and consistency.
Even qualified experts must be calibrated to produce consistent annotations. Calibration protocols include consensus-building sessions on difficult examples, inter-annotator agreement monitoring with regular reporting, guideline documentation that evolves as new edge cases are discovered, and periodic re-calibration tests to detect annotator drift over time.
The annotator skill atrophy risk.
A research finding published in Nature Medicine noted a concerning pattern: endoscopists who used AI assistance for three months saw their own detection rates decline after stopping. This suggests that over-reliance on AI outputs can dull human expertise. Well-designed HITL systems must guard against this by keeping annotators actively engaged in reasoning rather than passively confirming model outputs.
Cost-Benefit Analysis: Why HITL Pays for Itself
The economic case for human oversight AI training rests on a simple asymmetry: the cost of human review is predictable and bounded, while the cost of unreviewed AI failures is unpredictable and potentially catastrophic.
The cost of HITL
Human review adds direct costs to the annotation pipeline: annotator labor, expert specialist rates, platform and tooling infrastructure, quality management overhead, and the organizational overhead of maintaining a trained review workforce. For a typical production HITL system, human review costs are 15–30% of total annotation budget when combined with AI-assisted pre-labeling a substantial investment but far less than fully manual annotation.
The cost of not having HITL
Without human review, model failures propagate into production undetected. A content moderation model that drifts toward false negatives may expose users to harmful content generating legal liability, regulatory penalties, and reputational damage. A medical diagnostic tool that develops blind spots may miss conditions generating patient harm and product liability. A financial fraud model that develops biases may approve fraudulent transactions generating direct financial losses. These failure costs are not theoretical: published case studies include an airline chatbot that provided incorrect refund information, leading to legal liability, and healthcare AI failures traced not to architectural weaknesses but to mislabeled training data.
The ROI calculation
The ROI of HITL is best understood as risk-adjusted: the investment in human review pays for itself by preventing failures whose expected cost exceeds the cost of review. For low-stakes applications (product recommendations, non-critical content ranking), minimal HITL may suffice. For high-stakes applications (healthcare, autonomous systems, financial compliance), comprehensive HITL is not an optional enhancement it is a prerequisite for responsible deployment. The EU AI Act’s high-risk system requirements, which take effect in August 2026, make this explicit: human oversight is a legal obligation, not just a best practice. (For how HITL integrates with programmatic labeling approaches, see our post on [weak supervision Post 20].)
Building a HITL Practice: Where to Start
For teams implementing HITL annotation, the following sequence provides a practical starting framework:
Step 1: Map your risk surface. Identify which model outputs carry the highest consequences if wrong. These are your mandatory HITL review points the decisions where human oversight is non-negotiable.
Step 2: Set escalation thresholds. Define confidence-based, policy-based, and sampling-based escalation rules. Start conservative (more human review) and relax thresholds as you build confidence in the model’s reliability.
Step 3: Build the tiered review team. Recruit and calibrate annotators at the appropriate expertise level for each review task. Match domain specialists to specialized review queues.
Step 4: Close the feedback loop. Ensure that every human correction flows back into the training pipeline. Without this step, HITL is quality control but not improvement you catch errors but the model never learns from them.
Step 5: Monitor and iterate. Track human override rates, edge case frequency, inter-annotator agreement, and model performance over time. Use these metrics to refine escalation thresholds, update guidelines, and prioritize retraining.
Frequently Asked Questions
What is human-in-the-loop annotation?
Human-in-the-loop annotation is a methodology where human judgment is embedded continuously into the AI lifecycle from initial data labeling through production monitoring with humans reviewing, correcting, and validating machine outputs in an ongoing feedback loop.
What is human-in-the-loop machine learning?
HITL machine learning is a collaborative approach where humans actively participate in training, evaluating, and operating AI systems, providing guidance, feedback, and annotations that the model uses to improve its predictions over time.
What is edge case annotation?
Edge case annotation is the practice of identifying, collecting, and labeling rare or ambiguous examples that fall outside a model’s training distribution the data points where the model is most likely to fail and where failures have the highest consequences.
Why does AI still need human review?
AI systems struggle with ambiguity, cultural context, ethical judgment, novel situations, and subtle errors that their training data did not cover. Human oversight catches these failures, provides training signal for improvement, and maintains accountability for high-stakes decisions.
When should model outputs be escalated to human review?
Escalation triggers include low model confidence, disagreement between multiple models, policy-mandated review categories (safety-critical decisions), statistically anomalous inputs, and random sampling for ongoing quality auditing.
How much does HITL annotation cost?
HITL review costs typically represent 15–30% of total annotation budget when combined with AI-assisted pre-labeling. Expert reviewers in specialized domains command $50–$200 per hour. The cost is offset by preventing model failures whose consequences far exceed the review investment.