RLHF annotation is the process of collecting, labeling, and structuring human preference data supervised fine-tuning examples, pairwise response rankings, and safety evaluations to train reward models and align large language models with human values, quality expectations, and safety standards.
Every major LLM in production today ChatGPT, Claude, Gemini, Llama was shaped by reinforcement learning from human feedback. OpenAI’s InstructGPT research demonstrated that a 1.3-billion-parameter model fine-tuned with human feedback was preferred by evaluators over a 175-billion-parameter GPT-3 model without alignment. The finding reshaped the industry: post-training data quality can matter more than model size.
By 2025, reinforcement learning from human feedback became the default alignment strategy, with 70% of enterprises adopting RLHF or related methods like DPO, up from 25% in 2023, according to IntuitionLabs’ comprehensive review. Yet the annotation layer the human feedback for LLM training that makes the entire process work remains poorly documented. Producing 600 high-quality RLHF annotation examples can cost $60,000, roughly 167 times more than the compute expense for training, according to Second Talent’s 2026 analysis.
This guide breaks down how does RLHF work from the annotation perspective: what data annotators create at each stage, how preference ranking annotation LLM workflows are structured, how RLHF vs DPO comparisons affect annotation requirements, and how to write RLHF annotator guidelines that produce reliable training signals. If you are building, fine-tuning, or evaluating LLMs, RLHF data annotation is the most important investment in your alignment pipeline.
How Does RLHF Work? The Three-Stage Pipeline
Understanding how does RLHF work requires tracing the complete pipeline from pre-trained model to aligned assistant. The process unfolds in three stages, each with distinct annotation requirements.
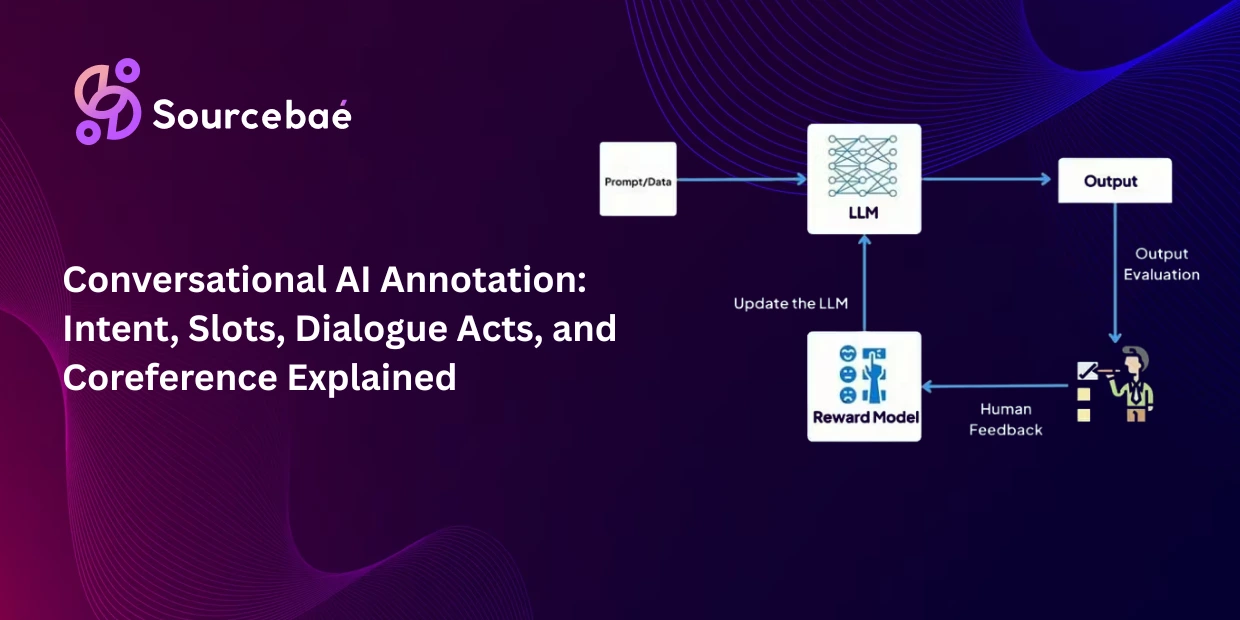
Stage 1 transforms a raw pre-trained model into an instruction-following assistant through supervised fine-tuning (SFT). Stage 2 trains a reward model on human preference rankings that captures what “good” and “bad” responses look like. Part 3 uses reinforcement learning (typically PPO) to optimize the model’s behavior against the reward model’s scores. Annotation is critical at Stages 1 and 2. Stage 3 is a computational optimization step that consumes the training signals annotation created.
Modern production alignment stacks in 2026 increasingly follow a pattern of SFT → Preference Optimization (DPO or PPO) → Safety tuning, with multiple rounds of refinement. Meta’s Llama 4 uses a three-step process combining SFT, rejection sampling, PPO, and DPO across multiple rounds. Anthropic’s Claude uses Constitutional AI combined with RLHF. The specifics vary, but every approach starts with human feedback for LLM training data.
Stage 1: Supervised Fine-Tuning Data Teaching the Model to Follow Instructions
Supervised fine-tuning (SFT) is the first stage where annotation directly shapes model behavior. Annotators create high-quality instruction-response pairs that teach the pre-trained model to follow user prompts, answer questions helpfully, and adopt the conversational style the deployment requires.
What annotators create
RLHF data annotation for SFT involves writing or curating examples of ideal model responses across diverse task categories. An SFT dataset might include question-answering pairs across general knowledge, science, history, and current events, coding tasks with correct solutions and explanations, creative writing prompts with high-quality responses, multi-step reasoning problems with clear chains of thought, summarization tasks with concise, accurate summaries, and safety-relevant examples demonstrating appropriate refusal of harmful requests.
Each example is an instruction-response pair: a user prompt and the kind of response the aligned model should produce. The quality bar is high SFT examples are not crowdsourced labels but carefully crafted demonstrations of ideal behavior.
Why SFT annotation quality matters
Research consensus in 2026 is that a moderately-sized dataset of very high-quality SFT examples outperforms a much larger dataset of mediocre quality. The industry has shifted toward curating hundreds to low thousands of expert-written examples rather than tens of thousands of crowdsourced responses. SFT establishes the model’s foundational abilities its instruction-following behavior, factual accuracy baseline, and conversational tone. Everything that follows (reward modeling, RL optimization) refines and aligns these abilities rather than creating them from scratch.
Stage 2: Reward Model Annotation Training the Quality Judge
Reward model annotation is the core of the RLHF process. Annotators evaluate pairs (or sets) of model-generated responses to the same prompt and rank them from best to worst. These preference rankings train a reward model a neural network that learns to predict a scalar quality score for any given response, capturing the nuanced judgment of “this response is better than that one.”
How preference ranking works
The annotation workflow for reward model annotation follows a structured process. The system generates a prompt typically sampled from a distribution representative of real user queries. The LLM generates two or more candidate responses to that prompt. A human annotator reviews all responses and ranks them from best to worst (or selects the preferred response in a pairwise comparison). The ranking is recorded as a preference pair: response A > response B, meaning A is preferred over B.
This preference ranking annotation LLM data thousands to hundreds of thousands of annotated preference pairs becomes the training set for the reward model. The reward model learns to assign higher scores to responses that humans preferred and lower scores to responses they rejected.
What annotators evaluate
Reward model annotation requires annotators to assess multiple quality dimensions simultaneously. Helpfulness asks whether the response actually answers the question or completes the requested task. Accuracy judges whether the factual claims in the response are correct and well-supported. Safety evaluates whether the response avoids harmful, biased, or dangerous content. Clarity considers whether the response is well-organized, easy to understand, and appropriately detailed. Instruction compliance checks whether the response follows the specific constraints in the prompt (format, length, tone).
Annotators must weigh these dimensions against each other a response that is highly helpful but slightly unsafe may be ranked below a response that is moderately helpful and completely safe. These trade-offs are where RLHF annotation becomes genuinely difficult, because different annotators may weigh safety versus helpfulness differently.
The disagreement challenge
Research shows that annotators disagree on 30–50% of subtle comparisons, reflecting genuine variance in human judgment. This is not annotation error it is the inherent subjectivity of evaluating complex, multi-dimensional response quality. Reward model annotation must account for this variance through multi-annotator labeling (3–5 annotators per comparison), calibration rounds that align annotator standards, inter-annotator agreement monitoring (targeting above 70–80% agreement on clear preferences), and adjudication protocols for resolving split decisions.
Stage 3: PPO Optimization How Annotations Become Alignment
In the third stage, the aligned model is trained using Proximal Policy Optimization (PPO) a reinforcement learning algorithm that adjusts the model’s behavior to maximize the reward model’s scores while staying close to the SFT model’s distribution (preventing “reward hacking” where the model exploits the reward function rather than genuinely improving).
Annotation is not directly involved in Stage 3 this is a computational optimization step. But the quality of the reward model (trained on Stage 2’s preference ranking annotation LLM data) determines the quality of the alignment signal. A reward model trained on inconsistent or low-quality preferences will guide the policy model toward inconsistent or low-quality behavior.
The KL divergence penalty a mathematical constraint that prevents the aligned model from deviating too far from the SFT baseline is critical for stability. Without it, models can “over-optimize” against the reward model, producing responses that score highly on the reward function but are repetitive, verbose, or unnatural. This is one of the most common failure modes in RLHF pipelines, and it traces back to reward model quality, which traces back to RLHF annotation quality.
RLHF vs DPO: How Annotation Requirements Differ
The RLHF vs DPO comparison is the most important architectural decision in LLM alignment today, and it directly affects annotation requirements.
Traditional RLHF (PPO-based)
The full RLHF pipeline requires three distinct annotation artifacts: SFT training data (instruction-response pairs), preference data for training the reward model, and the PPO optimization loop that uses the reward model. This is the most comprehensive approach it produces the most nuanced alignment but is also the most complex and expensive.
Direct Preference Optimization (DPO)
DPO, introduced by Stanford researchers in 2023, eliminates the separate reward model entirely. Instead of training a reward model on preference data and then running PPO, DPO trains the language model directly on preference pairs. The model learns to produce preferred responses without an intermediate quality scorer.
RLHF vs DPO in terms of annotation: DPO uses the exact same preference data format as RLHF. Annotators rank pairs of responses identically in both approaches. The difference is purely computational DPO processes the preference data differently during training, not during annotation. This means you can collect preference data once and use it for either approach (or both).
DPO reduces compute costs by 40–75% compared to RLHF and offers substantially more stable training. Hugging Face reported a 210% year-over-year spike in DPO usage by late 2024. However, a December 2025 study found that RLHF models produced unsafe outputs in only 8% of adversarial cases, compared to 10% for DPO-trained models suggesting RLHF retains an advantage for safety-critical applications.
RLAIF (Reinforcement Learning from AI Feedback)
RLAIF replaces human annotators with AI evaluators using a larger or more capable LLM to generate preference judgments based on a set of principles or a “constitution.” Anthropic’s Constitutional AI research demonstrated that models could learn safer behaviors without any human labels identifying harmful outputs.
RLAIF dramatically reduces annotation costs (AWS found 63% lower cost than RLHF on summarization tasks) and scales beyond what human annotation budgets allow. Google DeepMind demonstrated that RLAIF can match or exceed RLHF performance on multiple benchmarks. But RLAIF cannot teach the model knowledge beyond what the AI evaluator already possesses, and AI judges carry their own biases.
The 2026 production consensus
Gartner predicts 78% of enterprise LLMs will use SFT as the base, then layer on DPO or RLAIF for alignment not full RLHF. The emerging standard is selective alignment: SFT for 80–85% of training, DPO for general preference alignment, and RLHF only for safety-critical areas where the nuance of human judgment is irreplaceable. When evaluating RLHF vs DPO for your project, start with DPO (cheaper, simpler, easier to debug) and upgrade to RLHF only if safety evaluation metrics show a gap.
Annotation implications
Regardless of whether you choose RLHF, DPO, or RLAIF, the annotation requirements for preference ranking annotation LLM data remain similar. SFT data requires expert-written instruction-response pairs. Preference data requires ranked response pairs from qualified annotators. Safety data requires adversarial testing and red-teaming annotation. The choice between RLHF, DPO, and RLAIF affects how these annotations are processed during training not how they are created.
RLHF Annotator Guidelines: Writing Instructions That Produce Reliable Preferences
RLHF annotator guidelines are the most consequential annotation instructions you will ever write. Every bias, ambiguity, or inconsistency in your guidelines propagates through the reward model into the aligned LLM and affects every response the model generates for millions of users.
Essential components of RLHF annotator guidelines
Dimension definitions with explicit priority ordering. Define each quality dimension (helpfulness, accuracy, safety, clarity) and specify their relative priority. When a response is very helpful but slightly risky, which dimension wins? RLHF annotator guidelines must make this priority explicit otherwise, different annotators apply different hierarchies, producing contradictory preference signals.
Concrete examples at every quality level. For each rating level (or for each preference outcome), provide annotated examples showing why one response was preferred over another. Abstract instructions like “prefer more helpful responses” produce vague annotations. Specific examples like “Response A is preferred because it directly answers the question while Response B provides tangential background information” produce calibrated judgments.
Edge case protocols. Define how annotators should handle responses that are equally good (genuine ties), responses where both are poor (forced choice between bad options), responses involving contested or evolving factual claims, refusals (when should the model decline to answer?), creative tasks where “quality” is inherently subjective, and technical tasks where the annotator may lack domain expertise.
Safety-first escalation rules. When annotators encounter responses containing harmful content misinformation, bias, toxicity, privacy violations, dangerous instructions RLHF annotator guidelines should define clear escalation procedures. Safety-relevant preference decisions should be reviewed by senior annotators or safety specialists.
Calibration and continuous improvement
Discussions that automatically update guidelines and trigger annotator recalibration have been shown to increase inter-annotator agreement from 72% to 91%. RLHF annotator guidelines are living documents they must evolve as the model’s capabilities change, as new edge cases emerge, and as alignment priorities shift.
Schedule weekly guideline review sessions where annotators discuss disagreements on specific examples, update the guideline document with new edge cases and resolution decisions, and re-calibrate all annotators on the updated standards before resuming production labeling.
Common Pitfalls in RLHF Annotation
RLHF data annotation quality issues propagate through the entire alignment pipeline. Here are the most common failure modes.
Annotator fatigue on repetitive comparisons. After hours of evaluating similar response pairs, annotators develop decision fatigue defaulting to faster, less careful judgments. Rotate annotators between tasks, enforce break schedules, and monitor response time patterns (sudden speedups indicate declining attention).
Reward hacking through annotation artifacts. If annotators consistently prefer longer responses (a common bias), the reward model learns that length equals quality. The aligned model then generates unnecessarily verbose responses that score well on the reward function but frustrate users. RLHF annotation guidelines must explicitly address length bias and other systematic annotation preferences.
Insufficient diversity in annotator perspectives. If all annotators share similar demographics, cultural backgrounds, or political perspectives, the reward model learns a narrow definition of “quality” that may not represent the global user base. Human feedback for LLM training should come from diverse annotator pools that reflect the model’s intended users.
Over-alignment that kills creativity. Excessive safety optimization can produce a model that refuses benign requests, gives generic responses, and avoids any statement that could be interpreted as risky. The balance between safety and helpfulness is one of the hardest calibration challenges in RLHF annotation and it is fundamentally an annotation guideline problem, not a model architecture problem.
Training on stale preferences. User expectations and safety standards evolve. Preference data collected six months ago may not reflect current quality expectations. RLHF data annotation should be treated as a continuous process, with fresh preference data collected regularly to keep the reward model aligned with current standards.
The Annotator Expertise Requirement
RLHF annotation is not entry-level labeling work. The annotators evaluating LLM responses must be capable of assessing factual accuracy across diverse topics, identifying logical reasoning errors, detecting subtle biases and safety concerns, evaluating code correctness (for coding tasks), and judging writing quality, clarity, and tone.
For specialized domains, the expertise bar is even higher. STEM annotation projects require annotators with advanced degrees in mathematics, physics, biology, or chemistry. Coding projects require experienced software engineers who can spot logical errors across multiple programming languages. Medical and legal tasks require licensed professionals.
This expertise requirement is reflected in compensation. STEM-domain RLHF annotation pays $40+ per hour for specialists with advanced degrees. This is a fundamentally different cost structure than simple text classification or image labeling and it is why human feedback for LLM training represents such a large proportion of LLM development costs.
→ Related: [The Complete Guide to Data Annotation Methodologies in 2026] → Related: [How Data Annotation Powers the Machine Learning Pipeline] → Related: [Annotation Quality Metrics: Cohen’s Kappa, IAA, F1, and How to Measure What Matters] → Related: [Text Annotation for NLP: NER, Sentiment, Intent, Relation Extraction, and More] → Related: [Annotation for Conversational AI: Intent, Entity, Dialogue Act, and Slot Filling] → Related: [EU AI Act and Annotation Compliance: What Labeling Teams Must Know]
Frequently Asked Questions
What is RLHF annotation?
RLHF annotation is the process of creating human-generated training data for reinforcement learning from human feedback. This is the technique that aligns large language models with human preferences. It includes supervised fine-tuning data, such as expert-written instruction-response pairs. It also covers preference ranking data, where human annotators compare and rank model outputs. Safety evaluation data, including red-teaming and adversarial testing, is another key component. RLHF annotation is the most expensive annotation type per unit. It requires expert annotators who can evaluate factual accuracy, reasoning quality, safety, and nuance simultaneously.
How does RLHF work?
Reinforcement learning from human feedback works in three stages. Stage 1 (Supervised Fine-Tuning) trains the model on human-written instruction-response pairs to establish instruction-following behavior. Stage 2 (Reward Model Training) collects human preference rankings of model outputs and trains a reward model that predicts response quality. Part 3 (PPO Optimization) uses reinforcement learning to maximize the reward model’s scores while staying close to the SFT model’s behavior. The result is a model aligned with the quality, safety, and helpfulness standards encoded in the human preference data.
What is reward model annotation?
Reward model annotation has human annotators rank multiple model-generated responses to the same prompt, from best to worst. These preference rankings train a reward model. This is a neural network that learns to predict a quality score for any given response. Each annotation is a preference pair (Response A > Response B). It teaches the reward model what “better” means across helpfulness, accuracy, safety, and clarity. This is the most critical annotation stage in RLHF. The reward model’s quality directly determines the alignment quality of the final LLM.
What is the difference between RLHF vs DPO?
RLHF vs DPO represents the central architecture choice in LLM alignment. Traditional RLHF trains a separate reward model on preference data and then runs PPO to optimize the language model against that reward model. DPO eliminates the reward model entirely, training the language model directly on preference pairs. Both approaches use identical annotation data (preference rankings). DPO reduces compute costs by 40–75% and offers more stable training. RLHF retains a slight edge on safety (8% unsafe outputs vs. 10% for DPO in adversarial testing). The 2026 consensus: start with DPO, upgrade to RLHF only if safety metrics require it.
What should RLHF annotator guidelines include?
RLHF annotator guidelines should include explicit quality dimension definitions with priority ordering, such as helpfulness vs. accuracy vs. safety. They need concrete examples at every preference level showing why one response was chosen over another. Edge case protocols should cover ties, poor options, contested facts, refusals, and creative tasks. Safety escalation procedures for harmful content are essential. Guidelines should also address length bias mitigation rules and regular calibration schedules. Discussions that update guidelines and recalibrate annotators have been shown to increase inter-annotator agreement from 72% to 91%.
What is preference ranking annotation for LLMs?
Preference ranking annotation LLM is the specific annotation task where human evaluators compare two or more model-generated responses and rank them by quality. The annotator evaluates helpfulness, accuracy, safety, clarity, and instruction compliance to determine which response is preferred. These preference pairs form the training data for reward models (in RLHF) or direct policy optimization (in DPO). Annotators typically disagree on 30–50% of subtle comparisons, requiring multi-annotator labeling and calibration to produce reliable training signals.
What is RLAIF and how does it compare to RLHF?
RLAIF (Reinforcement Learning from AI Feedback) replaces human annotators with AI evaluators that generate preference judgments based on predefined principles. It reduces annotation costs by approximately 63% compared to RLHF and can match RLHF performance on many benchmarks. However, RLAIF cannot teach the model knowledge beyond what the AI evaluator possesses, and AI judges carry their own biases. The production standard in 2026 is hybrid: SFT for foundational abilities, DPO or RLAIF for general alignment, and RLHF annotation with human experts for safety-critical areas.
How much does RLHF data annotation cost?
RLHF data annotation is among the most expensive annotation types. SFT data curation costs $50–$200 per instruction-response pair for expert-written examples. Reward model annotation (preference ranking) costs $0.50–$3.00 per comparison for general annotators and $5–$15+ per comparison for domain specialists (STEM, medical, legal). Red-teaming and safety annotation costs $40–$100+ per hour for specialized evaluators. Producing 600 high-quality RLHF annotations can cost approximately $60,000. RLAIF and LLM-assisted pre-labeling can reduce costs by 40–75% for non-safety-critical preference data.