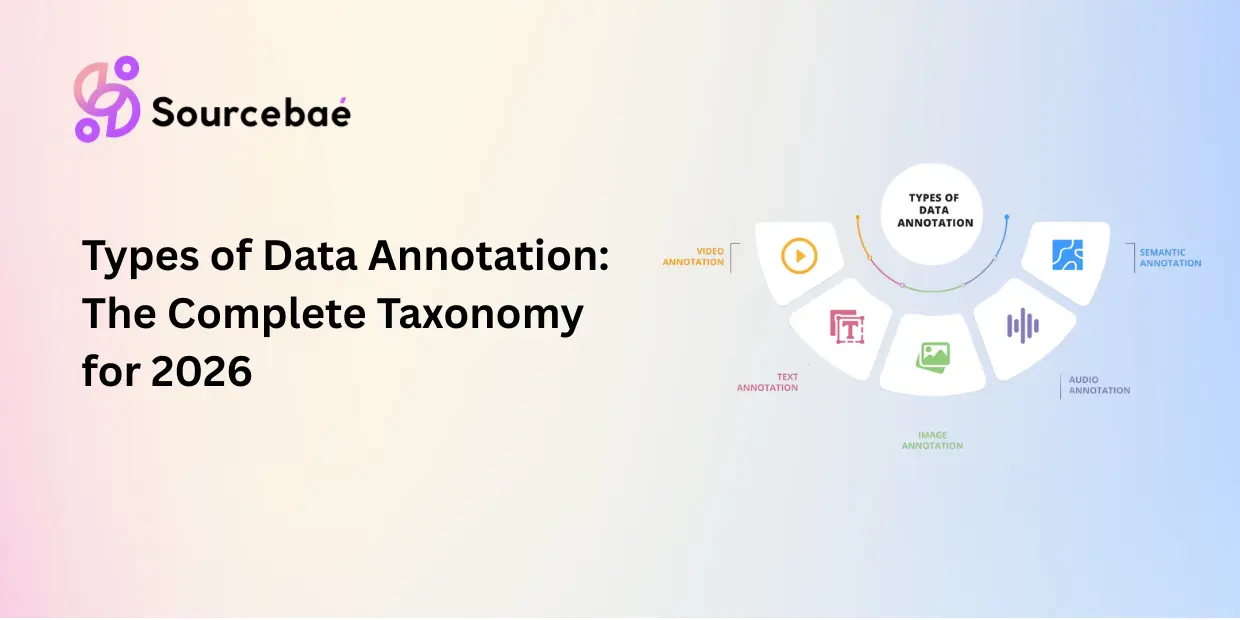

Machine learning models consume data in dozens of formats images, text, audio, video, 3D point clouds, satellite imagery, sensor streams, documents, and more. Each format demands its own annotation methods, tools, and quality benchmarks. Choosing the wrong types of data annotation for your use case wastes time and budget. Choosing the right one accelerates your model from prototype to production.
Data annotation types are the distinct methodologies used to label different formats of raw data from bounding boxes on images to named entity recognition in text to waveform tagging in audio so that machine learning models can learn structured patterns from unstructured inputs.
The global data annotation tools market is projected to grow from $2.14 billion in 2026 to $14.26 billion by 2034 at a CAGR of 26.76%, according to Fortune Business Insights. That growth is being driven by the expanding variety and complexity of data types AI models must process. Text annotation alone accounts for roughly 34% of the market, but image, video, 3D, and emerging modalities like multimodal and geospatial are gaining ground rapidly.
This post maps the complete taxonomy of annotation types in one place. Think of it as the table of contents for every annotation methodology that exists in production AI today. Each category includes a definition, its core methods, primary use cases, and a link to the dedicated deep-dive post in this series.
1. Image Annotation
What it is: The process of labeling visual data so computer vision models can identify, classify, locate, and segment objects within images. Image annotation is the most widely recognized annotation type and the foundation of applications from autonomous driving to medical diagnostics.
Core methods:
Bounding boxes draw rectangles around objects of interest. They are fast, cost-effective, and ideal for object detection tasks where pixel-precise boundaries are not required. A traffic monitoring model, for instance, uses bounding boxes to locate every vehicle in a frame.
Polygon annotation traces the exact shape of irregular objects, providing greater precision than bounding boxes for non-rectangular items like buildings in aerial imagery or organs in medical scans.
Semantic segmentation classifies every pixel in an image into a predefined category road, sidewalk, sky, vegetation without distinguishing between individual instances. It creates a full scene understanding at the pixel level.
Instance segmentation goes further by identifying each individual object separately, even when multiple objects share the same class. Two cars side by side are recognized as distinct instances, enabling counting, tracking, and spatial reasoning.
Panoptic segmentation combines semantic and instance segmentation into a unified output, labeling both “stuff” (uncountable regions like sky and grass) and “things” (countable objects like people and cars) simultaneously.
Keypoint annotation marks specific points of interest joints for pose estimation, facial landmarks for recognition systems, or anatomical reference points for medical analysis.
Primary use cases: Autonomous driving, medical imaging, retail product detection, manufacturing quality inspection, facial recognition, agricultural crop monitoring.
→ Deep dive: [Image Annotation Methods Explained: Bounding Boxes, Segmentation, Keypoints, and Polygons]
2. Text Annotation
What it is: The process of labeling linguistic data so natural language processing (NLP) models can understand, classify, and generate human language. Text annotation is the largest single segment of the annotation tools market, accounting for approximately 34% of market share, driven by the explosion of NLP applications across industries.
Core methods:
Named Entity Recognition (NER) identifies and classifies named entities people, organizations, locations, dates, monetary values within unstructured text. It is foundational for information extraction and knowledge graph construction.
Sentiment annotation labels text as positive, negative, or neutral. Essential for brand monitoring, customer feedback analysis, product reviews, and social media listening.
Intent classification categorizes user input by its underlying purpose a critical step in building chatbots, virtual assistants, and conversational AI systems.
Relation extraction labels the relationships between entities within text, such as “CEO_OF” or “LOCATED_IN,” enabling models to build structured knowledge from unstructured documents.
Coreference resolution identifies when different words in a text refer to the same entity (e.g., “Anthropic” and “the company” in the same paragraph).
Part-of-speech (POS) tagging labels each word with its grammatical function noun, verb, adjective supporting syntactic parsing and language understanding.
Text categorization assigns topic or category labels to entire documents or passages, powering content recommendation engines and document routing systems.
Primary use cases: Chatbots and virtual assistants, search engines, legal document analysis, clinical NLP, fraud detection, content moderation, machine translation.
→ Deep dive: [Text Annotation for NLP: NER, Sentiment, Intent, Relation Extraction, and More]
3. Audio and Speech Annotation
What it is: The process of labeling sound data so AI models can transcribe speech, identify speakers, detect emotions, and classify audio events. Audio annotation is a distinct discipline from text and image labeling it requires understanding of acoustics, speaker dynamics, and temporal structure.
Core methods:
Speech-to-text transcription converts spoken language to written text with timestamps. It is the foundation for voice assistants, meeting transcription, and accessibility tools. Annotators need native fluency and domain-specific vocabulary.
Speaker diarization identifies who spoke when in multi-speaker recordings, critical for meeting transcription, call center analytics, and podcast processing.
Emotion and sentiment detection classifies vocal tone, pitch, stress patterns, and emotional content in speech, supporting customer service analytics and mental health applications.
Sound event labeling tags non-speech audio events glass breaking, alarms, engine sounds, doorbells for security systems, industrial monitoring, and smart home devices.
Acoustic scene classification categorizes the overall environment of a recording street, office, restaurant, park providing contextual awareness for AI systems.
Primary use cases: Voice assistants (Alexa, Siri, Google Assistant), call center analytics, medical transcription, subtitle generation, music classification, security monitoring.
→ Deep dive: [Audio and Speech Annotation: Techniques for Voice AI, ASR, and Speech Models]
4. Video Annotation
What it is: The process of labeling visual data across sequences of frames so models can track objects, recognize activities, and understand scenes as they unfold over time. Video annotation extends every image annotation technique into the temporal dimension, adding the critical challenge of maintaining identity and consistency across frames.
Core methods:
Frame-by-frame annotation labels individual frames independently comprehensive but time-consuming. Suitable when precision matters more than speed.
Interpolation-based annotation labels keyframes and lets the tool automatically generate labels for the frames in between, dramatically reducing annotation time for smoothly moving objects.
Object tracking maintains the identity of a specific object across hundreds or thousands of frames, handling occlusion, re-entry, and scale changes.
Temporal segmentation divides a video into meaningful time segments individual actions, scenes, or events enabling activity-level understanding.
Activity and action recognition annotation labels what is happening in a video segment (walking, running, talking, falling), powering surveillance, sports analytics, and behavioral analysis systems.
Primary use cases: Autonomous driving, surveillance and security, sports analytics, robotics navigation, manufacturing quality control, retail behavior analysis.
→ Deep dive: [Video Annotation Techniques: Object Tracking, Temporal Segmentation, and Activity Recognition]
5. 3D Point Cloud and LiDAR Annotation
What it is: The process of labeling three-dimensional spatial data captured by LiDAR sensors, depth cameras, and 3D scanning technologies. 3D annotation is essential wherever depth perception, spatial reasoning, and volumetric understanding are required primarily in autonomous driving, robotics, and spatial computing.
Core methods:
3D bounding cuboids are the three-dimensional equivalent of bounding boxes, drawn as rectangular volumes around objects in 3D space.
3D semantic segmentation assigns a class label to every individual point in a point cloud, creating a fully labeled 3D scene.
Lane and road marking annotation labels drivable surfaces, lane boundaries, and road infrastructure critical for autonomous vehicle navigation.
Sensor fusion annotation combines and aligns labels across multiple synchronized data sources typically LiDAR with camera imagery and radar to create a unified ground truth.
Primary use cases: Self-driving cars, delivery robots, warehouse automation, urban planning, augmented reality, industrial digital twins.
→ Deep dive: [3D Point Cloud and LiDAR Annotation: Methods for Autonomous Driving and Robotics]
6. Geospatial and Satellite Imagery Annotation
What it is: The process of labeling aerial, satellite, and drone imagery for remote sensing AI. Geospatial annotation differs from standard image annotation because it must preserve coordinate systems, handle multi-spectral data beyond visible light, and account for resolution mismatches between training and deployment.
Core methods include land-use and land-cover classification, aerial object detection (buildings, vehicles, infrastructure), change detection annotation (comparing images from different dates), SAR (Synthetic Aperture Radar) annotation for all-weather monitoring, and spectral band annotation for material identification beyond the visible spectrum.
Primary use cases: Agriculture (crop monitoring, disease detection), defense and intelligence, disaster response, urban planning, deforestation tracking, climate research.
→ Deep dive: [Geospatial and Satellite Imagery Annotation: Methods for Remote Sensing AI]
7. Document and OCR Annotation
What it is: The process of labeling documents for AI models that need to understand document structure, extract key-value pairs, recognize tables, and process handwritten or printed text. Document annotation operates at the intersection of computer vision and NLP the model must see the layout and read the content simultaneously.
Core methods include document layout analysis (identifying headers, paragraphs, figures, tables), table detection and structure recognition, form field and key-value pair annotation, handwriting recognition annotation, receipt and invoice labeling, and OCR post-correction annotation.
Primary use cases: Financial document processing (invoices, contracts, tax forms), legal AI (contract analysis, compliance monitoring), insurance claims processing, healthcare records digitization, mail and logistics automation.
→ Deep dive: [Document and OCR Annotation: Layout Analysis, Table Extraction, and Form Field Labeling]
8. Time-Series and Sensor Data Annotation
What it is: The process of labeling sequential data that changes over time IoT sensor streams, physiological waveforms, financial time-series, and industrial equipment telemetry. Time-series annotation is distinct because annotators must identify patterns, events, and anomalies within continuous, often noisy signals.
Core methods include anomaly detection labeling (flagging unusual patterns in otherwise regular data), event tagging and segmentation (marking the start and end of specific events), waveform annotation for physiological signals (EEG, ECG, EMG), and predictive maintenance labeling (identifying early indicators of equipment failure).
Primary use cases: Healthcare monitoring (cardiac arrhythmia detection, sleep stage classification), industrial IoT (predictive maintenance, quality control), energy grid monitoring, financial fraud detection, environmental sensor networks.
→ Deep dive: [Time-Series and Sensor Data Annotation: Labeling for IoT, Industrial AI, and Healthcare Monitoring]
9. Search Relevance and Ranking Annotation
What it is: The process of labeling query-document pairs with relevance judgments so search engines and recommendation systems can learn to rank results effectively. This annotation type is the backbone of how search platforms from Google to enterprise search tools evaluate and improve their ranking algorithms.
Core methods include pointwise relevance grading (rating individual documents on a 1–5 relevance scale for a given query), pairwise preference judgments (determining which of two documents is more relevant), listwise ranking annotation (ordering a set of documents by relevance), and query intent annotation (classifying the underlying purpose of a search query).
Primary use cases: Web search engines, e-commerce product search, enterprise knowledge retrieval, content recommendation systems, ad relevance scoring.
→ Deep dive: [Search Relevance Annotation: How to Label Query-Document Pairs for Search and Recommendation Engines]
10. Content Moderation and Safety Annotation
What it is: The process of labeling content for platform trust and safety systems that detect and filter harmful material. Content moderation annotation trains the AI classifiers that operate at massive scale behind every major social media platform, marketplace, and communication tool.
Core methods include toxicity and hate speech classification, NSFW detection and labeling, policy violation categorization (specific to each platform’s rules), and misinformation and disinformation flagging.
Important consideration: Content moderation annotation exposes annotators to potentially harmful material. Ethical annotation practices including psychological support, exposure limits, and regular well-being check-ins are essential components of any responsible content moderation workflow.
Primary use cases: Social media platforms, online marketplaces, gaming communities, messaging applications, user-generated content platforms, ad review systems.
→ Deep dive: [Content Moderation Annotation: Labeling for Trust, Safety, and Platform Policy Enforcement]
11. RLHF and LLM Alignment Annotation
What it is: The process of collecting and labeling human preference data to train reward models that align large language models with human values, safety standards, and quality expectations. RLHF (reinforcement learning from human feedback) annotation is what transformed raw language models into the helpful, harmless assistants used by millions today.
Core methods include supervised fine-tuning data curation (creating high-quality instruction-response pairs), preference pair annotation for reward model training (ranking multiple model outputs from best to worst), DPO (Direct Preference Optimization) pair creation, and safety and red-teaming annotation (identifying harmful or unsafe model outputs).
Primary use cases: Large language model training (ChatGPT, Claude, Gemini), conversational AI alignment, code generation model improvement, creative writing model refinement, safety and policy compliance.
→ Deep dive: [RLHF Annotation: How Human Feedback Trains and Aligns Large Language Models]
12. Emerging and Specialized Annotation Types
Beyond the core categories above, several annotation types are gaining traction as AI extends into new domains.
Multimodal annotation labels data that spans multiple formats simultaneously text and images together, audio synchronized with video, or sensor data aligned with camera feeds. As foundation models become increasingly multimodal, cross-modal annotation is growing in both demand and complexity.
Weak supervision and programmatic labeling uses heuristic rules, labeling functions, and automated pipelines (such as the Snorkel framework) to generate approximate labels at scale, reducing dependence on manual annotation. Teams then refine these labels through human-in-the-loop review.
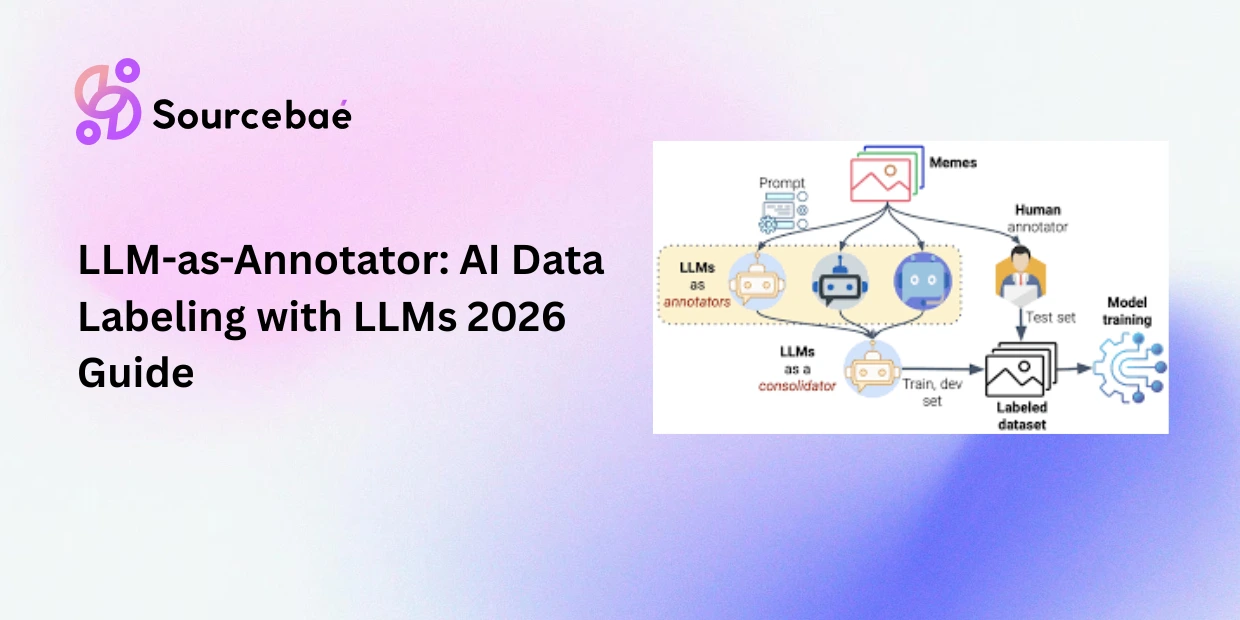
LLM-as-annotator leverages large language models themselves to generate zero-shot or few-shot labels, with human reviewers verifying and correcting the output. This approach can reduce labeling time significantly for straightforward tasks while still requiring human oversight for nuanced data.
Annotation for autonomous agents and robotics encompasses reward shaping, trajectory labeling, and environment annotation for reinforcement learning systems that operate in physical or simulated environments distinct from RLHF for language models.
→ Deep dives: [Multimodal Annotation] · [Weak Supervision and Programmatic Labeling] · [LLM-as-Annotator] · [Annotation for Autonomous Agents and Robotics]
How to Choose the Right Annotation Type
Selecting the correct annotation type is a function of three variables: the data format your model consumes, the task the model must perform, and the level of detail required for reliable predictions.
Start with the data format. If your raw data is images, you are working within image annotation. If it is text, you need NLP annotation methods. Audio, video, 3D, geospatial each format narrows the field immediately.
Then match the task. A classification task (sorting emails into categories) requires simple labeling. A detection task (finding objects in images) requires bounding boxes. A segmentation task (outlining exact boundaries) requires polygon or pixel-level annotation. A ranking task (improving search results) requires relevance judgments. The task determines which specific method within a category you need.
Finally, calibrate the detail level. More detail means richer training signals but higher cost and slower throughput. A prototype model can often succeed with simple bounding boxes. A production model for autonomous driving may require instance segmentation with 20+ attribute tags per object. Start with the minimum annotation complexity that meets your model’s performance requirements, then increase detail only where evaluation metrics show a gap.
When in doubt, run a pilot. Annotate a small batch (500–1,000 data points) using two different methods, train your model on each, and compare performance. Let the evaluation metrics not assumptions guide your annotation strategy.
Frequently Asked Questions
What are the main types of data annotation?
The primary data annotation types are image annotation, text annotation, audio annotation, video annotation, and 3D point cloud annotation. Additional categories include geospatial annotation, document and OCR annotation, time-series annotation, search relevance annotation, content moderation annotation, and RLHF annotation for large language models. Each type uses specialized methods tailored to its data format and AI use case.
Which data annotation type is most common?
Text annotation is currently the most prevalent, accounting for approximately 34% of the annotation tools market. This dominance is driven by the widespread use of NLP in chatbots, search engines, sentiment analysis, and document processing. Image annotation is a close second, powered by demand in autonomous driving, medical imaging, and retail AI.
What annotation types does autonomous driving use?
Autonomous driving relies on multiple annotation types simultaneously: image annotation (bounding boxes, segmentation for camera data), 3D point cloud annotation (cuboids and segmentation for LiDAR), video annotation (object tracking across frames), and sensor fusion annotation (aligning labels across camera, LiDAR, and radar). This multi-modal requirement makes autonomous driving one of the most annotation-intensive AI domains.
Can one tool handle all annotation types?
Most enterprise-grade annotation platforms support multiple data types. Labelbox, Scale AI, Encord, and V7 Labs handle image, video, text, and 3D annotation within a single platform. However, specialized tools may outperform generalist platforms for niche use cases like geospatial annotation (which requires GeoTIFF handling and coordinate system preservation) or audio annotation (which requires waveform editing and speaker diarization interfaces). Evaluate tools against your specific data format and annotation complexity.
How many annotation types does a typical AI project use?
Simple projects may use a single annotation type text classification for a chatbot, or image detection for a quality inspection system. Complex projects routinely combine multiple types. An autonomous driving system might use five or more annotation types across its full sensor suite. A healthcare AI platform might combine medical image annotation with clinical NLP annotation. As AI models become more multimodal, the average number of annotation types per project is increasing.