Enterprise AI Labs
Credentialed domain experts for frontier models
End-to-end post-training data - SFT, RLHF, red-teaming, evals - delivered by experts with verifiable credentials in medicine, law, engineering, finance, and research. Not crowdsourced. Not pre-screened. Credentialed.

Where most AI training pipelines break down
We've audited 60+ post-training pipelines across frontier labs and mid-market AI teams. Four failure modes show up in almost all of them.


Shadow domain coverage
Your medical reasoning benchmark plateaus at 72% because your annotators are pre-med students, not licensed physicians. The top-quartile jump requires people who've actually diagnosed patients.

Inconsistent quality signals
Inter-annotator agreement drops below 0.6 on specialist tasks when the vendor doesn't have a second layer of credentialed review. Your RLHF reward model learns the noise, not the signal.

Data-hidden procurement
You're three vendors deep, none of whom can tell you who actually labeled the data that trained your model. When eval regressions hit, you have no provenance trail.

Limited multilingual depth
Regional language coverage from most vendors means a bilingual college student — not a native speaker with verified educational credentials who can catch the cultural reasoning errors that tank your model in non-English markets.


Who actually does the work
Every expert on Sourcebae is credentialed before they touch your data. We verify degrees, licenses, and active practice. No exceptions.
Medicine
Licensed physicians and clinical specialists, credentials verified against national medical registries. Covers clinical reasoning, medical coding, diagnostic workflows, pharmacology, and radiology interpretation.
380+ active credentialed physicians
Engineering & Code
Senior engineers with production experience and graduates of tier-1 technical universities. Covers code RLHF across 20+ languages, system design evaluation, debugging traces, and chain-of-thought reasoning for software tasks.
1100+ active engineers
Law
Bar-admitted attorneys with active practice verification. Covers legal reasoning, contract review, case law analysis, and regulatory red-teaming across multiple jurisdictions.
930+ active licensed attorneys
Finance
Chartered Accountants, CFA charterholders, and credentialed financial professionals. Covers financial reasoning, audit workflows, tax logic, and quantitative red-teaming.
350+ active credentialed professionals
Research & PhDs
Doctoral researchers across STEM, social sciences, and humanities. Covers rubric design, expert-level eval construction, and domain-specific prompt engineering.
2800+ active researchers
Multilingual native speakers
Native speakers across 12+ regional languages and 18+ international languages, all with verified educational credentials in their language. Covers multilingual RLHF, cultural red-teaming, translation quality, and regional evaluation.
5000+ active native speakers
The Sourcebae data engine
Four layers between your SOW and your training run. Each layer is built on platform tooling we own, not spreadsheets and Slack.
Scoping with research partnership
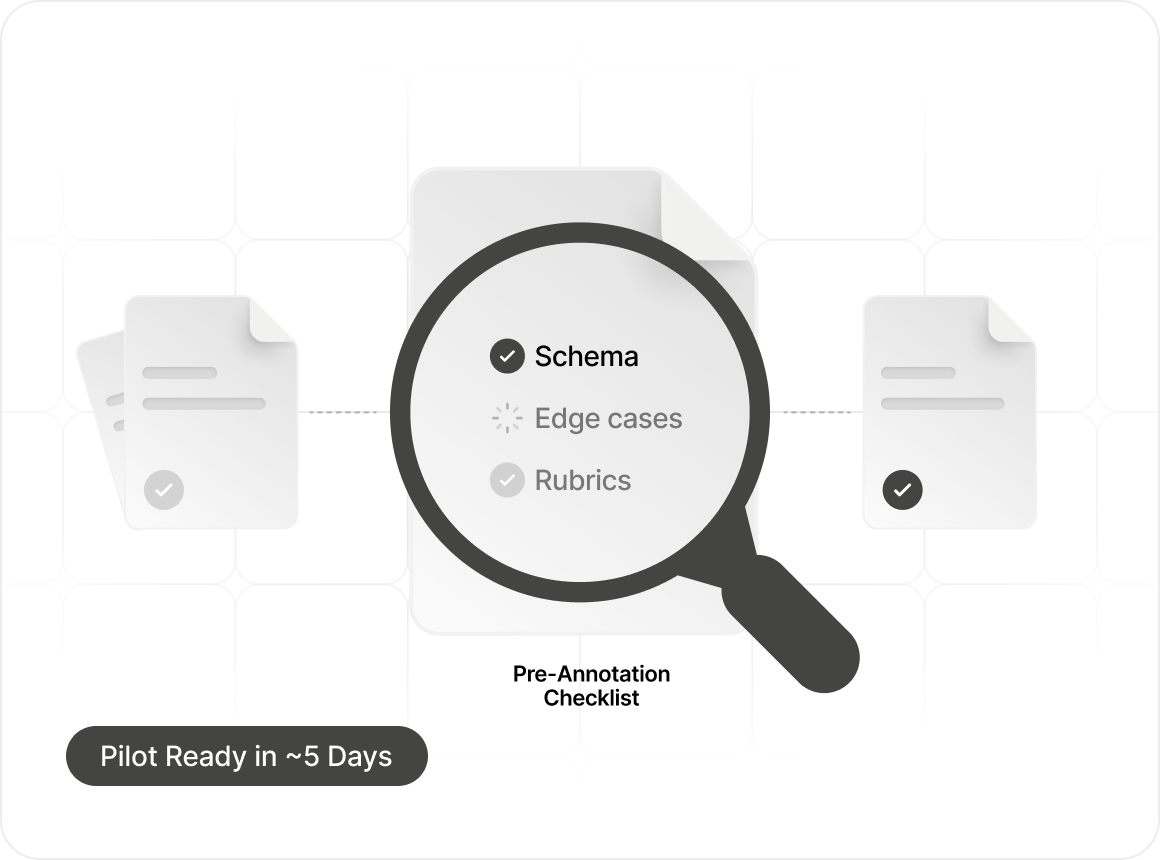
Our in-house research team partners with your post-training leads to define data schema, edge cases, and eval rubrics before a single annotator touches the task. Median scope-to-pilot: 5 business days.
SAIRA-powered expert matching
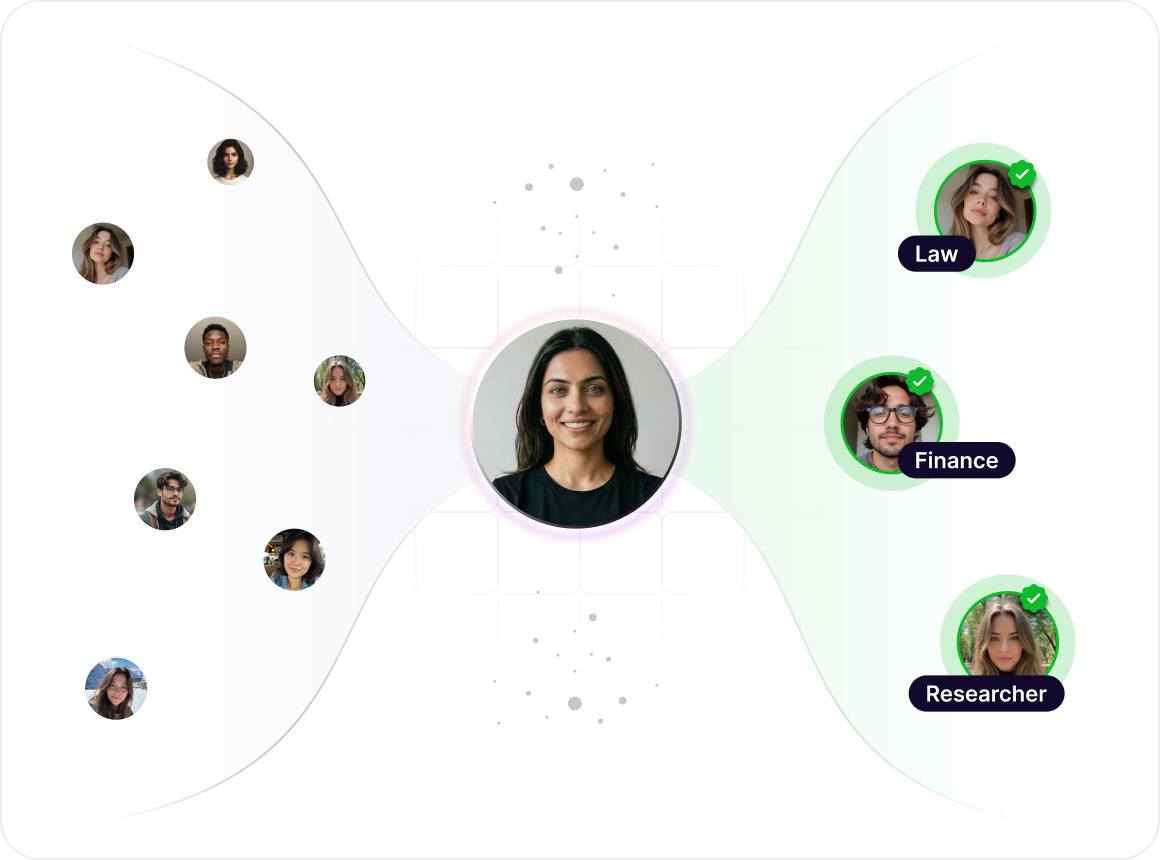
SAIRA, our AI vetting system, matches credentialed experts to your task by domain, specialization depth, and calibration score. Every expert has passed human-verified credential checks and task-specific calibration before joining your pipeline.
Managed production on the Sourcebae Platform
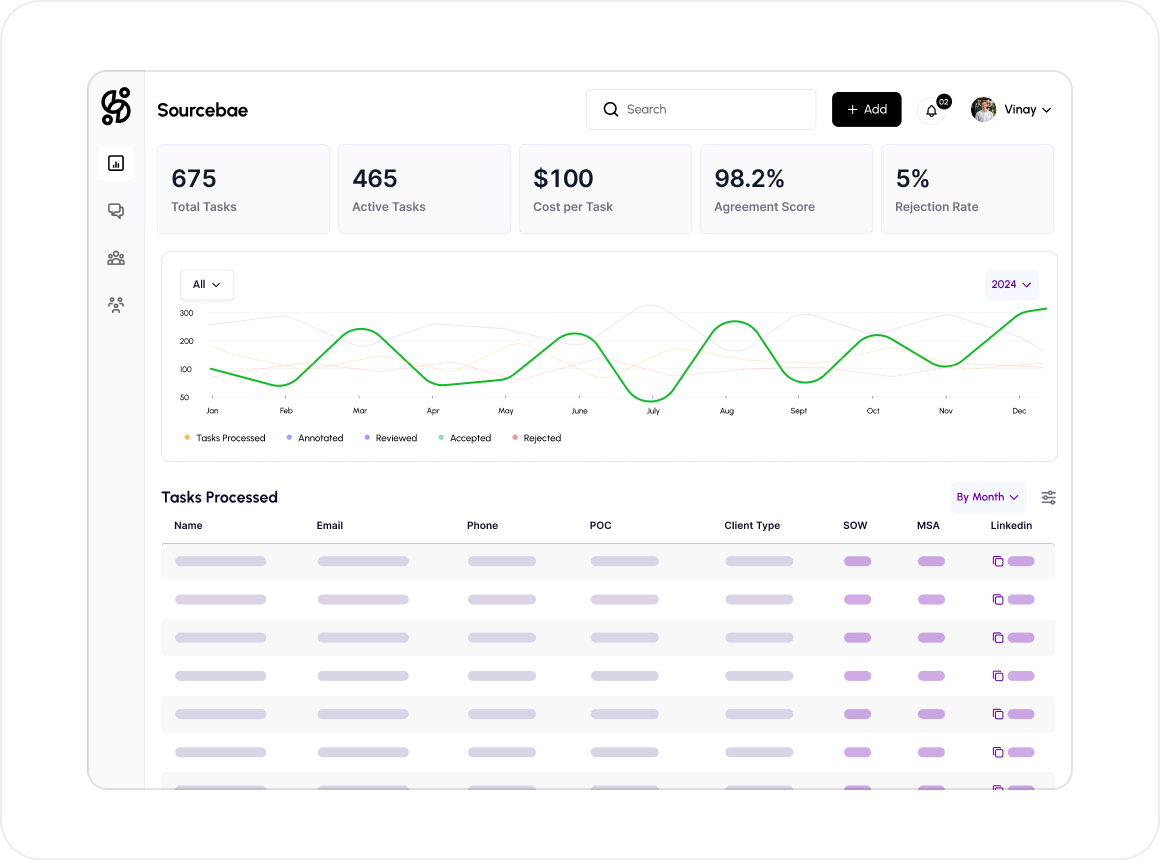
Live dashboards show throughput, inter-annotator agreement, rejection rates, and cost per task per domain. Your team sees what we see.
Multi-layer QA with credentialed review
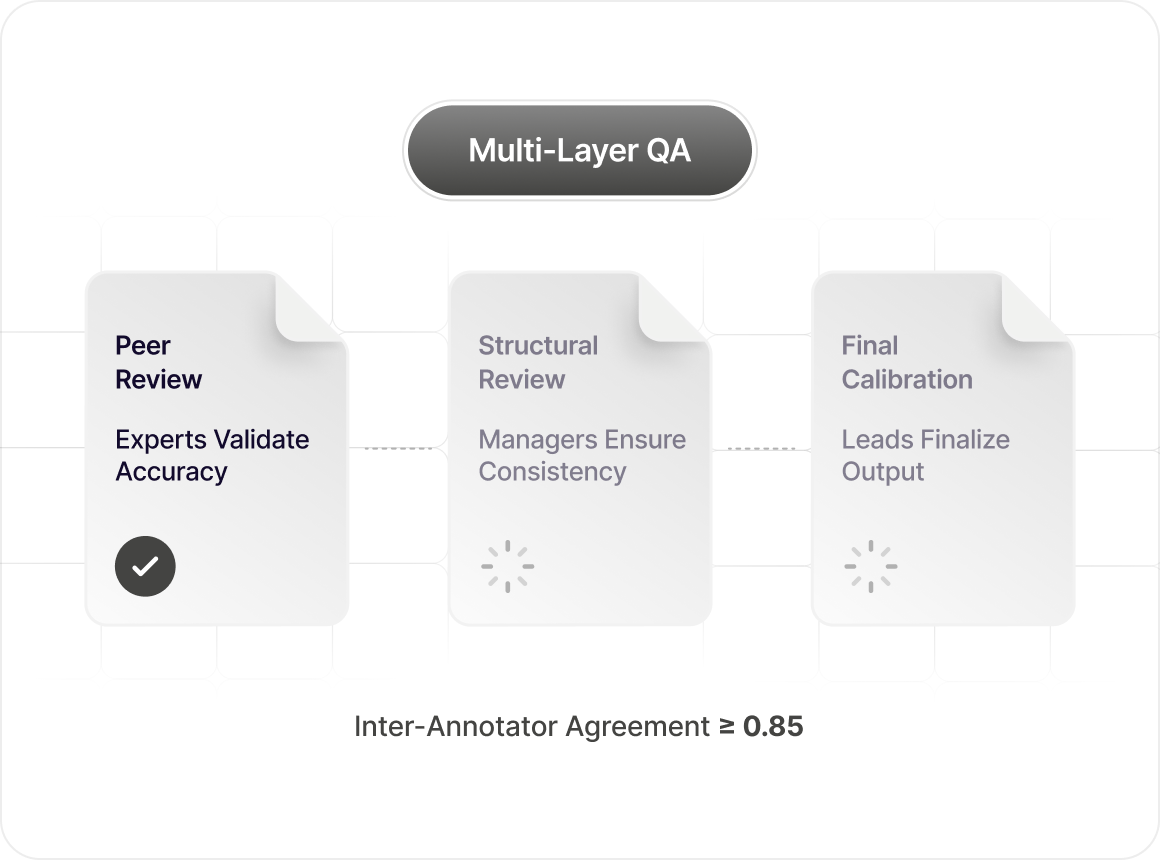
Every task passes through three review tiers: peer review by credentialed experts in the same domain, structural review by domain managers, and final calibration by our human data leads. Target inter-annotator agreement: 0.85+ on specialist tasks.
Every modality your post-training pipeline needs
Reasoning & evaluation
Chain-of-thought reasoning, rubric design, expert-level evals, multi-step reasoning traces.
RLHF & preference data
Pairwise preferences, SFT, preference modeling, reward model calibration.
Safety & red-teaming
Adversarial prompting, jailbreak discovery, harm-category red-teaming, compliance red-teaming.
Multimodal & frontier
Audio, video, egocentric video for robotics and physical AI, multilingual (12+ regional languages, 60+ total), code across 20+ languages.


Data that ships better models
Our clients don't just get annotated data - they get training signal that translates directly into benchmark improvements and faster release cycles.
3.7x

Faster ramp from SOW to first batch delivered
80+

Credentialed domains staffed and ready
0.91

Median inter-annotator agreement on specialist tasks
48h

Median time from project kickoff to first data delivery
Frequently asked questions
Sourcebae provides vetted human intelligence and domain experts to help AI labs and companies train, annotate, evaluate, and improve AI models.
©Sourcebae 2026 | All Rights Reserved