Most conversations about machine learning focus on models architectures, parameters, fine-tuning techniques. But the teams actually shipping AI to production know a different truth: the pipeline matters more than the model, and data annotation in machine learning is the stage where most projects succeed or fail.
Data annotation is the process that converts raw, unstructured data into labeled training examples at every critical stage of the machine learning pipeline from initial dataset construction through model evaluation, error analysis, and continuous improvement in production.
Industry reports consistently estimate that roughly 80% of machine learning effort is spent on data preparation and labeling rather than model development. VentureBeat has reported that 90% of data science projects never reach production, with the majority citing data quality issues as the root cause. AI development in 2026, as Humans in the Loop observed, no longer centers primarily on model architecture the industry has shifted toward a data-centric reality where training data quality is the primary constraint.
This post maps exactly where annotation fits at each stage of the ML pipeline, explains why data quality outweighs model complexity, and shows how to build the feedback loops that keep annotation and model performance improving together.
The Data-Centric AI Shift: Why Annotation Moved to Center Stage
For most of machine learning’s history, progress meant building bigger, more sophisticated models. Researchers competed on architecture innovation deeper neural networks, more parameters, cleverer training algorithms. Data was treated as a fixed input: collect a dataset, label it once, and focus all energy on the model.
That paradigm has shifted. The data-centric AI movement, championed by researchers like Andrew Ng and adopted by a growing number of production ML teams, argues that systematically improving data quality delivers more reliable performance gains than switching to a more complex model.
The logic is straightforward. If your training data contains inconsistent labels, missing edge cases, or biased class distributions, no model architecture can compensate. A state-of-the-art transformer trained on noisy labels will underperform a simpler model trained on clean, carefully annotated data. The model learns what the data teaches and if the data teaches the wrong patterns, the model reproduces them.
This realization has elevated annotation from a preprocessing chore to a core engineering discipline. In 2026, the most effective ML teams treat their annotation pipeline with the same rigor they apply to their model training pipeline: versioned guidelines, measurable quality metrics, automated monitoring, and continuous iteration.
Where Annotation Fits at Every Pipeline Stage
The machine learning pipeline is not a straight line. It is a cycle of interconnected stages, and annotation touches nearly all of them. Here is how the data annotation process integrates with each stage of a production ML workflow.
Stage 1: Data Collection and Curation
Every ML project begins with raw data images captured by cameras, text scraped from documents, audio recordings from call centers, sensor streams from IoT devices. At this stage, the annotation’s role is indirect but critical: the annotation requirements you define determine what data you need to collect.
A team building an autonomous driving model does not just collect random road footage. The annotation schema the set of object classes, attributes, and edge cases the model must learn dictates the collection strategy. If the schema includes “pedestrian carrying an umbrella in rain,” the team must specifically collect data from rainy conditions. Annotation requirements drive data collection, not the other way around.
Data curation also plays a role here. Modern tools use embedding-based data selection and active learning algorithms to identify the most diverse and informative samples from a large pool of raw data, prioritizing the subset that will provide the highest value once annotated. This prevents teams from wasting annotation budget on redundant or low-value data.
Stage 2: Data Preprocessing and Preparation
Before annotation begins, raw data typically requires cleaning and standardization. Images may need resizing, cropping, or normalization. Text may need tokenization, deduplication, or format conversion. Audio requires noise normalization and segmentation. Video requires frame extraction or downsampling.
Annotation guidelines are drafted at this stage the detailed written instructions that tell annotators exactly how to apply each label, handle edge cases, and manage ambiguous data. The quality of these guidelines directly determines the quality of the annotations that follow. Vague guidelines produce inconsistent labels; precise guidelines produce clean training data.
Stage 3: Annotation Execution
This is the stage most people think of when they hear “data annotation” the actual process of applying labels to data. Annotators (human, AI-assisted, or a combination) work through the prepared dataset and add the metadata that transforms raw inputs into structured training examples.
In practice, annotation execution involves several parallel processes. Task assignment routes data to annotators based on their expertise and the complexity of each item. Real-time quality checks flag potential errors as annotators work. Progress tracking monitors throughput, cost, and completion timelines.
The annotation workflow itself varies by method and data type. Image annotation might involve drawing bounding boxes and assigning class labels. Text annotation might involve highlighting named entities and tagging sentiment. RLHF annotation involves comparing model outputs and ranking them by quality. Each methodology has its own tools, interfaces, and quality benchmarks.
AI-assisted pre-labeling has become standard practice in 2026. Machine learning models generate initial annotations, and human reviewers verify and correct them. This approach, sometimes called model-in-the-loop annotation, can reduce labeling time by 40–60% while maintaining or even improving quality because human attention is focused on corrections rather than starting from scratch.
Stage 4: Quality Assurance and Validation
Annotation without quality assurance is a gamble. This stage verifies that the labels applied during execution meet the project’s accuracy requirements before the data enters the training pipeline.
Standard QA practices include multi-annotator consensus (having two or more annotators independently label the same data and measuring agreement), expert adjudication (a senior reviewer resolves disagreements), gold standard benchmarking (testing annotators against a pre-labeled reference set), and automated consistency checks (flagging statistical outliers, missing labels, or impossible attribute combinations).
The quantitative metrics that drive QA decisions Cohen’s Kappa, Fleiss’ Kappa, Intersection over Union (IoU), and F1 scores are covered in detail in our dedicated post on annotation quality metrics. The key principle is that quality must be measurable, not assumed. If you are not tracking inter-annotator agreement as a number, you do not actually know how good your annotations are.
MIT research has found that even best-practice benchmark datasets contain at least 3.4% inaccurate labels. That may sound small, but across millions of training examples, a 3.4% error rate introduces tens of thousands of incorrect signals that can systematically bias a model’s predictions.
Stage 5: Model Training
Once annotated data passes quality validation, it enters the training pipeline as structured input-output pairs. The model learns to map raw inputs (an image, a sentence, an audio clip) to the labels annotators have assigned (a bounding box, an entity tag, a transcription).
Annotation quality manifests directly in training dynamics. Clean, consistent labels produce stable loss curves, faster convergence, and more reliable evaluation metrics. Noisy or contradictory labels create unstable training, slow convergence, and evaluation scores that fluctuate unpredictably between runs.
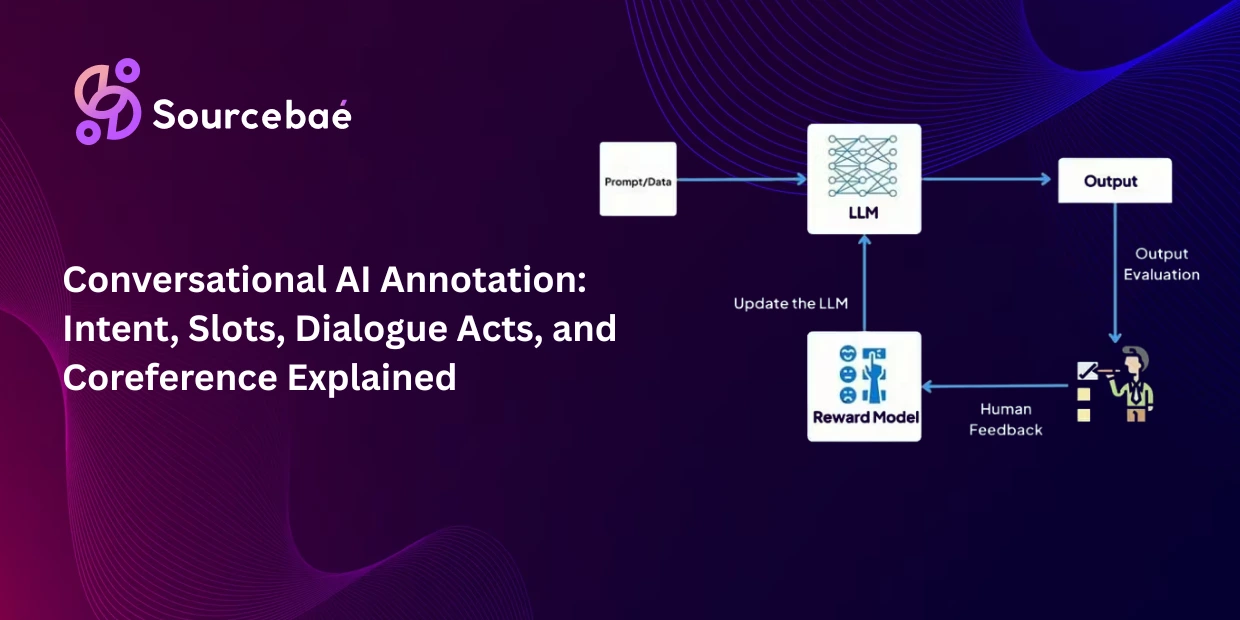
For large language models, the annotation process extends beyond initial training into fine-tuning and alignment. Supervised fine-tuning data carefully curated instruction-response pairs teaches the model to follow instructions. RLHF annotation human preference rankings of model outputs trains the reward model that aligns the LLM with human values, safety standards, and quality expectations.
Stage 6: Model Evaluation and Error Analysis
After training, the model is evaluated on a held-out test set data the model has never seen during training, but that has been annotated with the same rigor as the training set. The accuracy of these evaluation annotations is paramount: if the test set labels are wrong, the evaluation metrics are meaningless.
Error analysis is where annotation and model development interact most directly. When the model makes mistakes, the team examines the errors and categorizes them. Common findings include situations where the model fails because annotation guidelines were ambiguous on a particular edge case, where an entire class of objects was underrepresented in the training data, where label inconsistencies in the training set taught the model conflicting patterns, or where real-world conditions (lighting, noise, language variety) were not adequately represented in the annotated dataset.
Each finding generates a specific annotation action: revise guidelines, collect and annotate more data for underrepresented cases, re-annotate inconsistent subsets, or expand the annotation schema to cover new conditions.
Stage 7: Deployment and Continuous Monitoring
Deploying a model to production does not end the annotation pipeline it creates a new data source for it. Production models encounter data that differs from their training distribution: new objects, unfamiliar language, unexpected sensor conditions. When the model’s confidence drops, or users report errors, this real-world data becomes the next batch of annotation work.
Continuous human-in-the-loop (HITL) systems operationalize this cycle. When a deployed model encounters an input it has low confidence in, it flags that data for human review. An annotator provides the correct label, and the corrected example feeds back into the next retraining cycle. This continuous feedback loop is the only reliable path from 95% accuracy to the 99.9% required for safety-critical deployments.
Production monitoring also surfaces data drift gradual changes in the input distribution that degrade model performance over time. A fraud detection model trained on 2024 transaction patterns may see accuracy erode as spending behavior shifts in 2026. Regular re-annotation of fresh production data keeps the model aligned with current reality.
The Annotation Feedback Loop: Why One-Time Labeling Is Not Enough
The most common mistake in annotation strategy is treating it as a one-time project. A team collects data, labels it, trains a model, and moves on. Six months later, production performance has degraded, edge cases are accumulating, and the model is quietly making errors no one has measured.
The solution is building annotation as a continuous pipeline not a one-time batch. Here is what that looks like in practice.
Guideline versioning. Just as code is versioned, annotation guidelines should be versioned. When the team discovers an edge case that existing guidelines do not cover, the guidelines are updated, and the version is recorded. This creates a traceable history of how labeling standards evolved and enables teams to re-annotate historical data against updated criteria when needed.
Active learning prioritization. Instead of randomly selecting data for annotation, active learning algorithms identify the samples the model is most uncertain about and route those to human annotators first. This maximizes the value of each annotation dollar by focusing human effort where it has the greatest impact on model performance.
Error-driven re-annotation. When error analysis reveals systematic labeling inconsistencies, the affected subset of training data is re-annotated under revised guidelines. This is more efficient than annotating entirely new data because the core dataset is already collected and preprocessed.
Production data integration. Fresh data from production especially flagged low-confidence predictions and user-reported errors is continuously funneled into the annotation pipeline. This keeps the training distribution aligned with the real-world distribution the model encounters daily.
Teams that implement this feedback loop consistently outperform those that treat annotation as a one-and-done task. Their models improve with each cycle, their guidelines become more precise, and their annotation costs per unit of model improvement decrease over time as the system learns where human effort is most valuable.
Common Pipeline Failures Caused by Annotation Problems
Understanding where annotation failures damage the pipeline helps teams prioritize prevention. The most frequent failure modes include the following.
Guideline ambiguity is causing inconsistent labels. When two annotators can reasonably interpret the same data point differently because guidelines do not cover that scenario, the training data contains contradictory signals. The model learns an average of conflicting patterns and performs poorly on all of them.
Class imbalance from non-strategic data collection. If rare but critical classes (emergency vehicles, unusual medical conditions, edge-case fraud patterns) are underrepresented in the annotated dataset, the model never sees enough examples to learn them reliably. It defaults to the majority class and misses the cases that matter most.
Label leakage between training and evaluation sets. If the same annotator labels both training and test data using the same systematic interpretation, the evaluation metrics will appear higher than real-world performance justifies. The model is not actually better the test set just shares the same biases as the training set.
Stale annotations after data drift. A model trained on annotated data from 2024 may be deployed into a 2026 world where user behavior, language patterns, visual environments, or sensor conditions have changed. Without ongoing re-annotation with current data, performance degrades silently.
Insufficient annotation depth for the task. A model that needs to locate and measure objects requires bounding boxes or segmentation masks, not simple class labels. Choosing an annotation methodology that is too shallow for the model’s task creates a ceiling on achievable performance that no amount of model tuning can break through.
Building Your Annotation Pipeline: A Practical Checklist
For teams designing or improving their annotation workflows, the following checklist captures the essentials discussed throughout this post.
Define the annotation schema before collecting data. Your schema the classes, attributes, relationships, and edge cases your model must learn determines what data you need. Schema-first planning prevents expensive re-collection later.
Write detailed, versioned guidelines with visual examples. Include positive examples, negative examples, and borderline cases for every class. Update guidelines as new edge cases surface and record each version.
Select annotators matched to task complexity. Use generalists for simple classification. Use domain experts for specialized tasks where subject-matter knowledge impacts label accuracy. The 2026 industry trend is strongly toward expert-led annotation.
Implement measurable quality assurance. Track inter-annotator agreement (Cohen’s Kappa or Fleiss’ Kappa) for classification tasks and IoU for spatial tasks. Set minimum thresholds and do not promote data to training without meeting them.
Automate where it helps but keep humans in the loop. Use AI-assisted pre-labeling to accelerate throughput. Use active learning to prioritize high-value samples. But maintain human review for all labels, especially in high-stakes or ambiguous domains.
Build feedback loops from production back to annotation. Route low-confidence predictions and error reports from deployed models to the annotation pipeline. This keeps your training data aligned with reality and your model improving with each cycle.
Treat annotation as infrastructure, not a project. Invest in tooling, process, and workforce development as permanent capabilities. The teams that treat annotation as core infrastructure build compounding advantages that widen over time.
Frequently Asked Questions
What is the role of data annotation in the machine learning pipeline?
Data annotation provides the labeled training examples that supervised machine learning models learn from. It is involved at nearly every pipeline stage: it drives data collection strategy, defines the training signal during model training, supplies the ground truth for evaluation, informs error analysis, and continues through production via feedback loops. Without annotation, the pipeline has no structured data to train on.
How much time do ML teams spend on data annotation?
Industry estimates consistently report that ML teams spend roughly 80% of their effort on data preparation and labeling, with only 20% devoted to model development and tuning. This ratio reflects the data-centric reality of modern AI improving data quality yields more reliable performance gains than improving model architecture.
What is data-centric AI, and how does it relate to annotation?
Data-centric AI is an approach that prioritizes systematic improvements to data quality through better annotation, cleaner guidelines, and tighter quality control over changes to model architecture. Instead of asking “can we build a better model?”, data-centric teams ask “can we build better training data?” This philosophy places annotation at the center of the ML improvement cycle.
Why do most ML projects fail to reach production?
Studies cite data quality issues as the leading cause. VentureBeat reported that 90% of data science projects do not reach production, with poor or insufficient training data as a recurring factor. Inconsistent labels, class imbalance, missing edge cases, and stale annotations all contribute to models that perform well in development but fail in the real world.
What is a continuous annotation feedback loop?
A continuous feedback loop connects model performance in production back to the annotation pipeline. When the deployed model makes low-confidence predictions or errors, that data is routed to human annotators for labeling and fed back into the next retraining cycle. This loop keeps training data aligned with real-world conditions and enables models to improve over time rather than degrade after deployment.
Should annotation happen before or after model training?
Both. Initial annotation creates the training dataset before the first model is trained. But annotation continues after training through error analysis (re-annotating data the model gets wrong), evaluation set construction (labeling held-out test data), and production feedback loops (labeling new data flagged by the deployed model). Annotation is a continuous process, not a one-time event.