SAIRA · The Human Intelligence Engine for AI
Vetting domain experts is hard. SAIRA makes it defensible.
One wrong annotator. A million wrong outputs. SAIRA verifies real expertise. Across 22+ verticals. In 40+ languages.

A bad expert means a bad model
Confident generalists pass most interviews.
They also poison your training data.
Generic AI tools test communication.
They don't test real expertise.
For frontier AI work, "seems competent" is
not vetting. It's a liability.

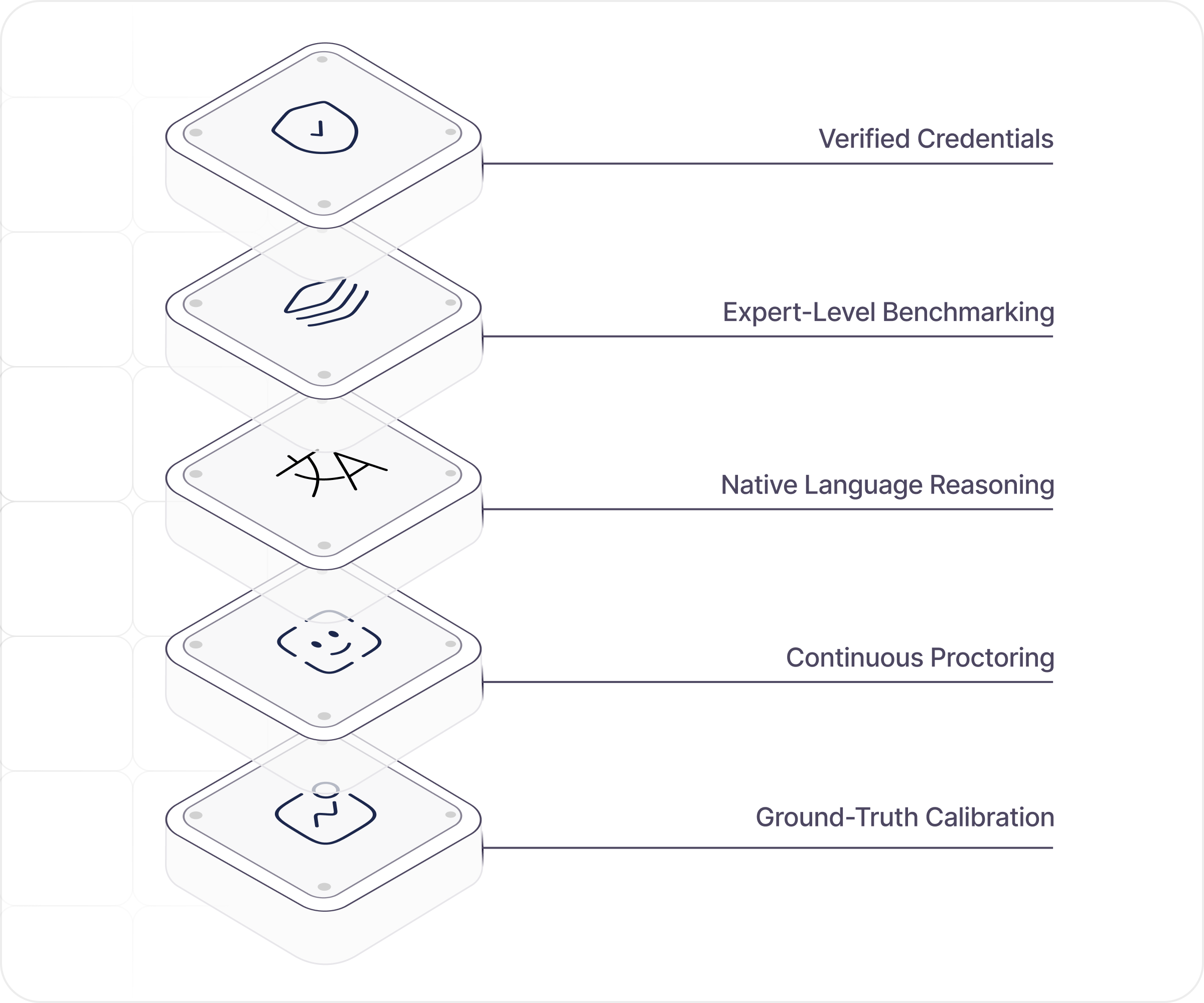
Three layers.
One uncompromising standard

Domain expertise graph
Every vertical mapped to senior-practitioner depth. Tested against that depth. Not a checklist

Native-language evaluation
Technical fluency in 40+ languages. Real reasoning. Not translation.

Fraud-proof proctoring
Technical fluency in 40+ languages. Real reasoning. Not translation.
Four signals. No shortcuts.
Depth, not breadth
Three layers deeper than a standard interview. A radiologist reasons through ambiguous scans. Not definitions.
Adaptive follow-ups
Every answer triggers the next question. Surface-level responses get probed. Memorized answers fall apart.
Edge cases over textbooks
Real expertise lives in gray areas. SAIRA tests judgment. Pretenders default to vague language.
Reasoning trail, not just verdict
Every score shows its work. Your team sees why an expert passed. Not just whether.
A bar set by senior practitioners. Held without exception.
Credential verification: Validated against issuing bodies. AIIMS, IIT, Bar Councils, ICAI, medical councils. No self-declarations.
Domain depth assessment: The expertise graph is built with senior practitioners. The standard is peer-acceptable. Not recruiter-acceptable.
Language-native reasoning: A Marathi annotator is tested in Marathi. By an engine that understands Marathi technical vocabulary.
Behavioral integrity: Proctoring runs continuously. Identity, attention, and response patterns. Monitored end-to-end.
Calibration against ground truth: Scoring calibrated against expert panels. Drift monitored monthly. Standards don't slip.
Your model is only as good as the experts behind your data

RLHF & preference data
Shallow expertise rewards shallow answers. SAIRA-vetted experts produce real signal.

Red-teaming
Finding model failures needs people who know where models fall. SAIRA matches expert, language, and threat surface.

Evaluation & benchmarking
Frontier evals need credentialed reviewers. Not crowd workers. Every score is defensible.

Multilingual coverage
A model serving 40 languages can't be evaluated in 3. SAIRA brings native depth to every market.
22+ verticals, 40+ languages. Real depth in every one.
Verticals

Languages

SAIRA vs. Generic
AI Interviewers
Generic AI
Interviewer
SAIRA Domain
Edition
Tests communication
Tests domain depth
Native-language reasoning
Credential verification
AI-assist fraud detection
Reasoning trail per score
Calibrated against expert panels
Audit trail for compliance
Use cases
For AI Labs
Credential experts for RLHF, evaluation, and red-teaming across languages your model serves.
For Enterprises
The same vetting rigor. Applied to in-house hiring.
For Staffing Partners
SAIRA plugs into your pipeline. White-label available.

Frequently asked questions
Same engine. Deeper layer. Adds the expertise graph, native-language evaluation, and AI-lab grade proctoring.
©Sourcebae 2026 | All Rights Reserved